过去很长一段时间里,我对 SSD 的了解仅限于其和 HDD 的区别和一个标签化的「速度快」认知,至于其什么时候快,为什么快却鲜有了解。直到最近开始研究数据库时,发现数据库设计和存储发展和特性紧密联系,不可分割,于是才开始回过头关注起 SSD 的结构和原理,猛然发现之前关于 SSD 有许多非常错误的认识。
SSD 的基本结构
在了解 SSD 性质前,简单回顾下 SSD 的基本结构组成,下面是两张 SSD 的架构图:
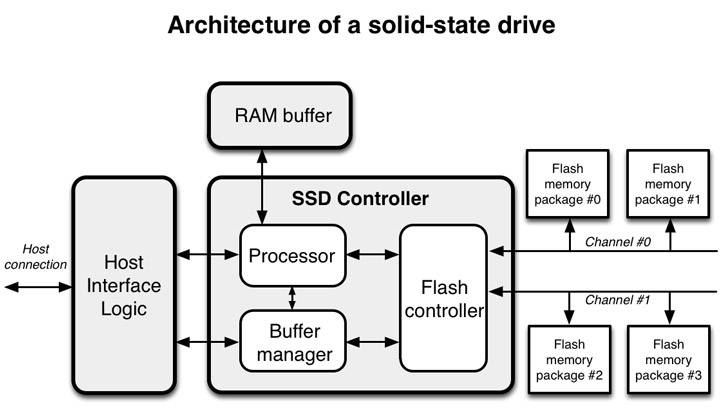

其中,SSD Controller 用以执行耗损平衡、垃圾回收、坏快映射、错误检查纠正、加密等功能。相比与 HDD,它的工作非常繁重,而这些工作极大地影响了 SSD 的性能表现,后文会详细谈到。SSD 内部的闪存(Flash)由一个个闪存单元组成,每个闪存单元都有一个寿命,超过寿命将导致坏块。常见有三种闪存单元类型:
- SLC:每个单元 1 比特
- MLC:每个单元 2 比特
- TLC:每个单元 3 比特
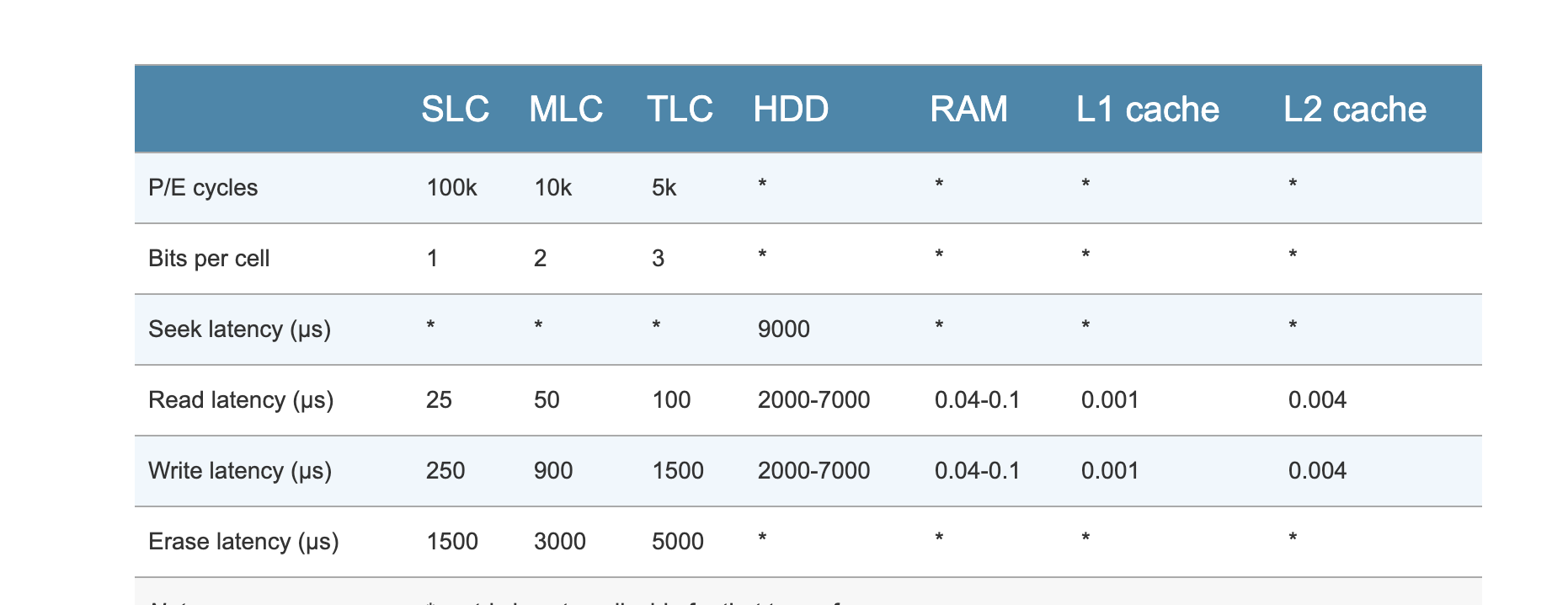
每种 NAND 类型有不同的性能和寿命表现,如下表:
闪存单元内部由一个个 Block 组成,每个 Block 由多个 Page 组成。
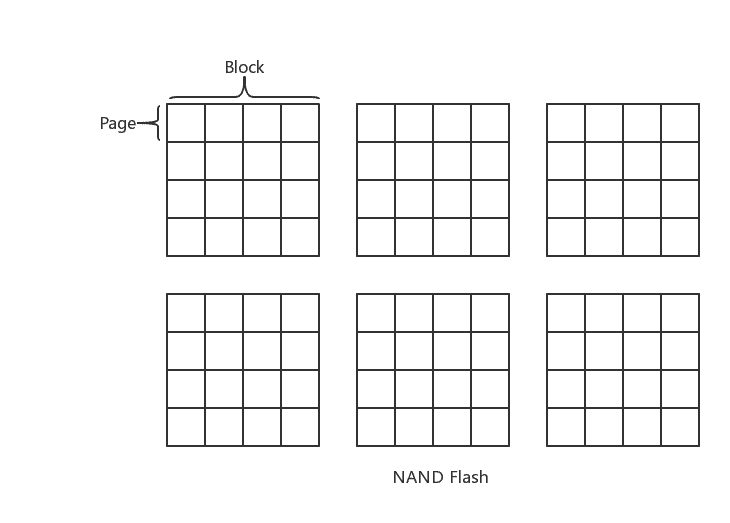
对于闪存的访问有以下限制:
- 读写数据只能以 Page 为单位
- 擦除数据只能以 Block 为单位
每个 Page 大小一般为 2 KB 到 16 KB,这意味着使用 SSD 时,哪怕读或写 1 Byte 的数据,SSD 依旧会访问整个 Page。
此外,SSD 并不允许覆盖的操作,当原本 Page 中已有数据时,只能先删除再写入,为了加快写入速度,一般 SSD 修改数据时,会先写入其他空闲页,再将原始页标记为 stale ,直到最终被垃圾回收擦除。
SSD 内部工作细节
垃圾回收
SSD 在擦除整个 Block 时,需要先整理其中的 Page,腾出没有活跃 Page 的 Block 进行擦除。此过程中,原本的一次写入最终有可能会隐式牵涉到多个 Page 的移动,导致出现写入放大的现象。因此垃圾回收是一个耗时且容易影响寿命操作。
垃圾回收一般是一个后台操作,但当出现写入速度超过了回收速度时,SSD 会启动前台垃圾回收,此时必须等待待写入 Block 被擦除才能继续写入,从而严重影响写入延迟。
由于垃圾回收的存在,我们可以发现,频繁地修改一个文件是不利于 SSD 寿命和性能表现的。

逻辑地址转换
SSD 内部会维护一个逻辑地址到物理地址的映射。程序不需要关心物理地址,由 SSD 的 FTL (Flash Translation Layer)进行映射转换。
这样做的好处是,对于应用程序来说,文件地址依旧是连续的,而真实存储的时候可以由 FTL 算法决定分配到哪些空闲页上。
损耗均衡
NAND 内存单元存在 P/E 循环限制,所以都会有一个固定的寿命。如果出现热点块反复写入数据,很快这个块的寿命就会耗尽,导致容量变小。由于有了前面的逻辑地址转换,所以物理地址可以由 SSD Controller 控制映射关系,从而可以实现损耗均衡。SSD Controller 会平均利用每个 Block 的寿命,使得各个 Block 的寿命在同一时间达到他们的 P/E 循环限制而耗尽。
断电保护
一些 SSD 中设有超级电容,这个电容设计为存有足够提交总线中所有 I/O 请求所需的能量以防掉电丢失数据。
SSD 并行处理
SSD 有四种层次的并行处理方式:
- Channel-level parallelism
- Package-level parallelism
- Chip-level parallelism
- Plane-level parallelism
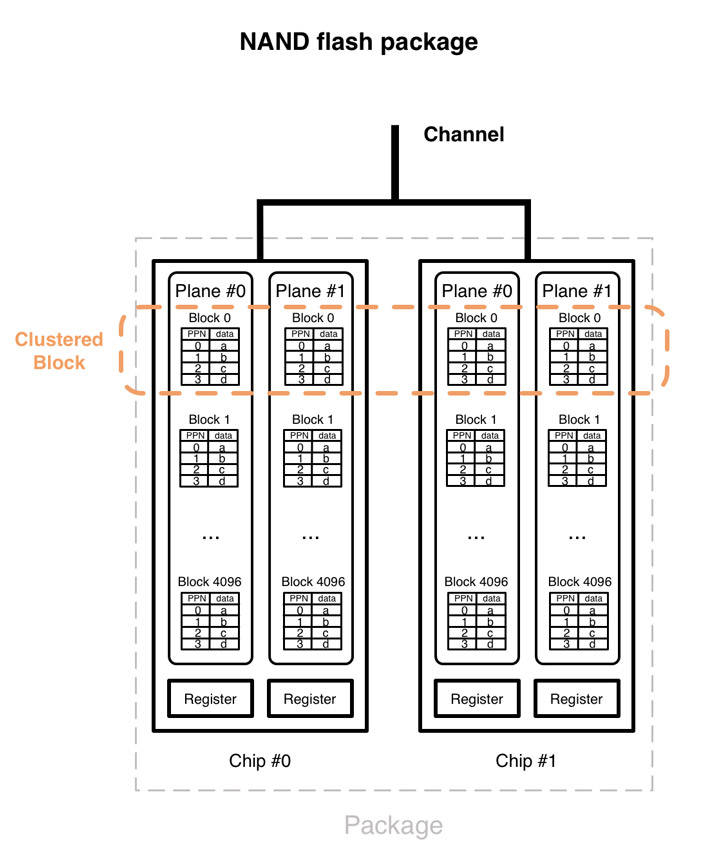
SSD 内部将不同芯片中的多个 Block 组成一个 Clustered Block。单次数据写入可以通过 Clustered Block 并行写入到不同 Block 中。由此可以发现,即便是单线程的写入,在 SSD 层也能实现并发的写,当然前提是写入的数据大于整个 Clustered Block 的大小。另外,对于这类大数据的写入,单线程性能甚至优于多线程,多线程写入会有更大的延迟。
如何正确读写 SSD
了解访问模式
定义
- 如果 I/O 操作开始的逻辑块地址(LBA)直接跟着前一个 I/O 操作的最后LBA,则称值为顺序访问
- 如果不是这样,那这个I/O操作称为随机访问
不同访问模式的速度
通常来说,即便是对于 SSD,随机读写也会比顺序读写要慢很多,最恶劣情况下甚至相差10倍。
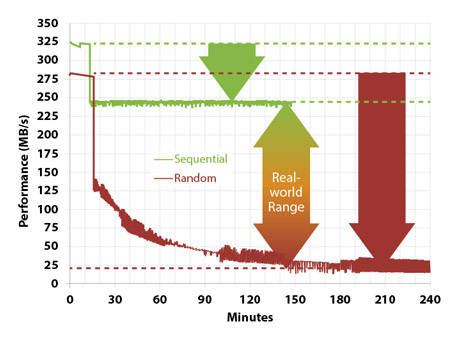
随机读的问题在于:
- 不能利用预读功能提前缓存数据
- 每次 IO 需要重新定位物理地址
随机写的问题在于:
- 造成大量磁盘碎片,极大地增加了垃圾回收的压力
- 小数据量的随机写无法利用 SSD 内置的并发能力
但是如果随机写入能够按照 Clustered Block 大小对齐,那么利用 SSD 并行的能力,随机写入能够达到和顺序写入同样的吞吐量。
如果仔细观察上图还会发现在一开始无论是随机读写还是顺序读写,性能都非常高,这是因为一开始所有 Page 都是空闲的,完全不需要垃圾回收,所以两者表现差异不大,但当磁盘被写满过一次以后,垃圾回收的压力使得随机读写性能一落千丈。这也是为什么 SSD 一买来测试速度会表现非常好,而之后越来越慢的原因。
和 HDD 的区别
对于 HDD,修改一个数据并不需要进行「读取-擦除-写入」的过程,而是可以直接就地(in-place)更新,所以许多许多数据结构被设计成 in-place 的方式,但对于 SSD 这种更新会给垃圾回收带来巨大负担,既影响寿命也影响性能。
按读方式设计写方式
对于一些经常被一起访问的数据(如关系型数据的单条记录),写时最好一次同时写入,这样做的好处是:
- 如果能够在单 Page 内容纳下,读取时只读取单 Page
- 如果需要多个 Page 才能容纳,写入时会并行写入到 Clustered Block,读取时也能一次并行读取
冷热分离读写
如果有一行记录:
name,birthday,visted_count
由于这行数据非常小,所以基本会落到同一个 Page 上,而 visted_count 这个值是一个典型的热数据,name,birthday 是典型的冷数据,此时每次用户访问时去更新 visted_count 都会导致整个 Page 的数据被挪动和重写。
对于这类不得不变更的热数据,好的做法是先放在内存中,定期刷盘,从而避免频繁修改磁盘。
使用单线程进行大写入/读取
大 IO 能够充分利用 SSD 并行特性,读写延迟更短。