本地内存缓存是一个在基础软件架构中非常常见的基础设施,也正因其过于常见,以至于平时很少去思考它是如何实现的。在尚未设计缓存系统前,完全没想到原来要需要考虑如此多复杂的事情。本文将由浅入深介绍如何设计一个现代的高性能内存缓存系统。
什么时候需要本地内存缓存
在大部分业务系统中,都会使用诸如 Redis、Memcached 等远程缓存,一方面可以避免自身进程内存占用过大而导致的 OOM 或 GC 问题,另一方面也可以实现多个进程共享同一份一致的缓存数据。但对于某些底层服务(例如数据库服务),远程缓存的网络延迟是不可接受的,这就势必需要引入本地内存缓存。
本地内存缓存的特点
本地内存缓存可被视作一个基于本地内存的 「KeyValue 数据库」。但相比较于传统数据库而言,它对一致性的要求十分宽松:
- 对于更新与删除的操作,需要保证强一致性
- 对于插入操作可以容忍少量丢失
- 对于读取操作可以容忍少量 Miss
与磁盘数据库的另一个不同之处在于,磁盘数据库的设计有一个前提假设是磁盘是可以随需要而不断扩容的,倘若一个磁盘数据库因磁盘占满而崩溃主要责任是在使用方。而内存缓存则没有这么宽容的假设可以建立,它必须考虑到内存是昂贵且有限的这一事实。
除此之外,由于本地内存缓存处于业务进程当中,所以其需要考虑更多业务向的问题,比如:
- 由于自身大量老生代的内存占用,是否会对所处进程产生 GC 问题。
- 当多线程场景下,如何同时解决线程安全、数据竞争、高吞吐等问题。
- 需要能够适应一些非随机的访问统计规律,例如 Zipf。
综上所述,我们可以归纳出对一个优秀的本地内存缓存系统的要求:
- 线程安全
- 高吞吐
- 高命中率
- 支持内存限制
实现路径
在实现一个完整的缓存系统前,我们需要将目标一步步拆解。
首先为了实现缓存逻辑,我们必须有一个类 Map 的 KeyValue 数据结构,同时它必须是线程安全的。为了支持内存限制,我们必须要能够驱逐一些 key,所以需要实现一个驱逐器。为了实现驱逐的同时维持高命中率,我们还需要告诉驱逐器每个 key 的访问记录,让它能够从中分析出哪些 key 可以被驱逐。综上分析,我们可以整理出一个大概的 Roadmap:
- 实现一个线程安全的 Map 数据结构:存储缓存内容
- 实现一个访问记录队列:存储访问记录
- 实现一个驱逐器:管理缓存内容
本文所有代码均使用 Golang 编写。
线程安全的 Map
简易的 Map
cache := map[string]string{}
cache["a"] = "b"
在 key 数量固定且极少的情况下,我们一般会用原生 Map 直接实现一个最简单缓存。但 Golang 原生 Map 并不是线程安全的,当多个 goroutine 同时读写该对象时,会发生冲突。
线程安全的 SafeMap
type SafeMap struct {
lock sync.Mutex
store map[string]string
}
func (m *SafeMap) Get(k string) string {
m.lock.Lock()
defer m.lock.Unlock()
return m.store[k]
}
func (m *SafeMap) Set(k, v string) {
m.lock.Lock()
defer m.lock.Unlock()
m.store[k] = v
}
这是一个最简单的线程安全 Map 实现。对于访问量很小的系统,这已经能够成为一个非常方便快速的实现了,但需要注意的是,这个 Map 是被该进程下的所有线程所共享的,任何一个修改都需要去竞争得到一个锁,如果套用数据库领域的概念,这个锁就是数据库级别的锁,显然对于并发量大的时候是不适合的,会成为整个系统的瓶颈。
分段锁的 SafeMap
type SafeMap struct {
locks []*sync.Mutex
store []map[string]string
}
func NewSafeMap() SafeMap {
return SafeMap{
locks: []*sync.Mutex{{}, {}, {}},
store: []map[string]string{{}, {}, {}},
}
}
func hash(k string) int {
h := fnv.New32a()
h.Write([]byte(k))
return int(h.Sum32())
}
func (m *SafeMap) GetLock(k string) *sync.Mutex {
idx := hash(k) % len(m.locks)
return m.locks[idx]
}
func (m *SafeMap) GetStore(k string) map[string]string {
idx := hash(k) % len(m.locks)
return m.store[idx]
}
func (m *SafeMap) Get(k string) string {
lock := m.GetLock(k)
lock.Lock()
defer lock.Unlock()
return m.GetStore(k)[k]
}
func (m *SafeMap) Set(k, v string) {
lock := m.GetLock(k)
lock.Lock()
defer lock.Unlock()
m.GetStore(k)[k] = v
}
一个很自然的想法是将 key 进行分桶,从而分散对锁的竞争。这种方法类似于将「数据库锁」打散成「表锁」。到这一步,我们基本已经完成了一个最简单的高并发缓存。
读写分段锁的 SafeMap
考虑到缓存系统读远大于写,我们可以对上述 Map 的互斥锁 Mutex 改为 RWMutex ,从而使得读时并不互斥,改善读性能。
使用线程 ID 实现无锁
需要注意的是,上述 Map 中,我们使用的分桶方法是利用 key 做随机哈希,这种做法只能缓解锁竞争的问题,却无法根治。那么是否有办法根治这里的锁竞争呢?
办法和代价都是有的。如果我们可以让某一块内存只被某个线程访问,那么就可以完全避免这些线程之间的锁竞争,从而实现无锁。假设每一个线程都有一个线程ID,我们可以按线程ID去分段,每个线程独占一个 SafeMap。
这样做虽然避免了锁,但也同时造成了数据「膨胀」。如果同一个 key 被N个线程 Set 了多次,此时内存中就多了 N 份同样的数据。如果它只被 Set 了一次,也将导致其他线程没法取得这个数据,从而出现非常高的 Miss 率。但对于那些极其热门的少量 key,这种方式的确可以作为一种优化选择。
令人遗憾的是,在 Golang 中,由于 GPM 调度模型的存在,在 Runtime 中屏蔽了线程所有相关信息,所以我们是没有正常的办法获得「线程ID」的信息,因而此文暂不考虑上述方案。
使用 sync.Map 实现无锁
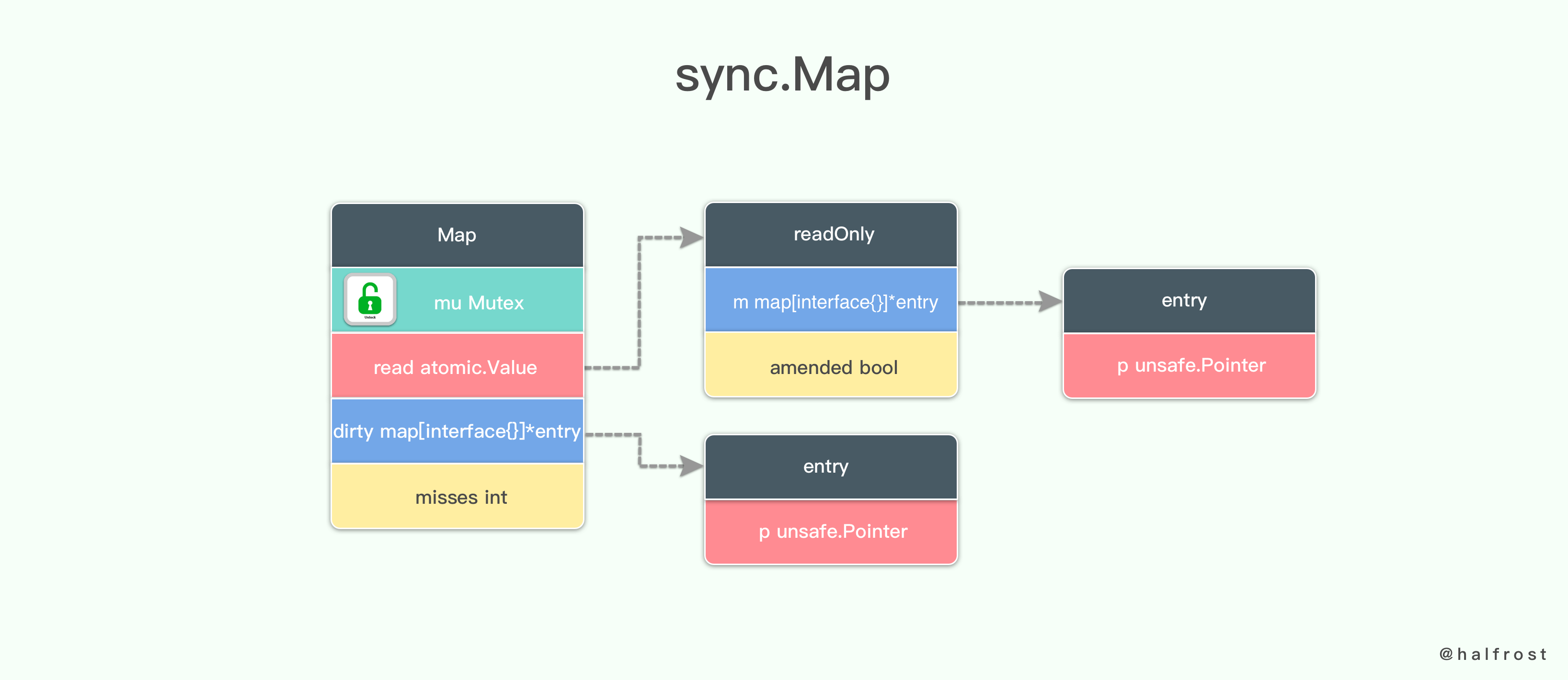
图片来源: 如何设计并实现一个线程安全的 Map ?(下篇)
准确来说,sync.Map 并不是完全的「无锁」,只是一个在绝大部分读场景是无锁的线程安全 Map。具体原理可以参见相关文档。但由于其底层实现并未采取分段锁的方法,所以写的时候会有一个 dirty 上的全局锁,进而会影响到高并发写时的性能。所以对于不在乎写性能同时写也相对不密集的时候,该数据结构是非常理想的选择。
设计
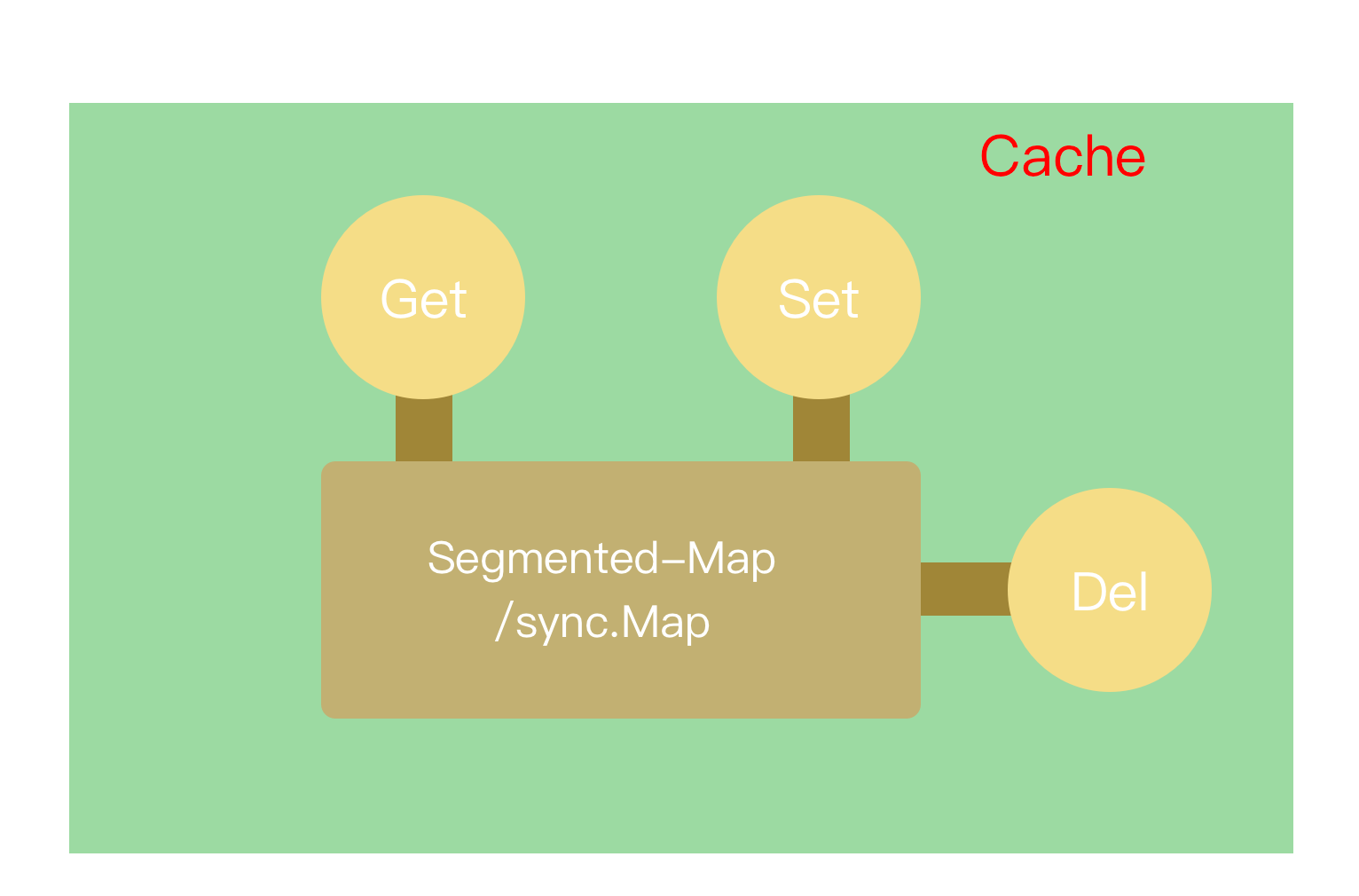
访问记录队列
对于访问记录的读写,同样牵涉到多线程同时操作同一个内存地址的情况。但我们对其一致性会比缓存内容存储更低,尤其是在高并发数据的假设下,少量的数据丢失并不会影响最终判断结果。
与缓存内容存储的场景不同的是,对于访问记录,每次 Get/Set 的时候都会需要进行一次写入操作,所以它的写速度要求远高于前面的缓存内存存储。更为关键的是,即便是在如此高密度的写情况下,它也同样需要保证线程安全。
虽然上述要求看似十分复杂,我们依然可以试着通过几个方面的分析,来拆解这个问题。
在性能方面,我们需要保证该数据结构写入时是无锁的,因为一旦有锁,前面做的降低锁颗粒度优化都会被这个有锁的结构给拖累。
在写入方式方面,由于我们可以接受少量数据丢失,并且我们没有非常实时的要求,所以我们可以接受异步的写入。
在存储内容方面,我们只需要存储 Key 数据。
根据上述分析,我们不难发现我们需要的是一个基于内存的线程安全的无锁 Lossy 队列。但似乎并没有现成的这种数据结构实现,所以我们可以退一步将这个问题变成,先实现一个 Lossy 队列,再在此基础上,实现线程安全的功能。
环形缓冲:RingBuffer
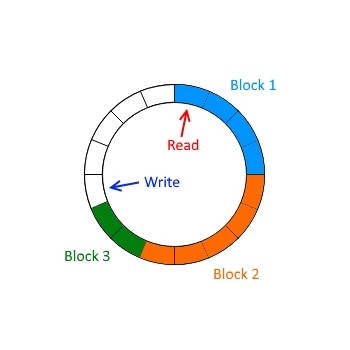
RingBuffer 是一个非常简单的环形缓冲队列,由一个数组,加上一个读指针和写指针构成。读指针永远只能读到写指针前的数据。
线程安全支持:sync.Pool
Golang 自带的 sync.Pool 可以非常好地和 Ring Buffer 协同工作,实现在近乎无锁的情况下,构造出一个线程安全的高吞吐缓冲队列。
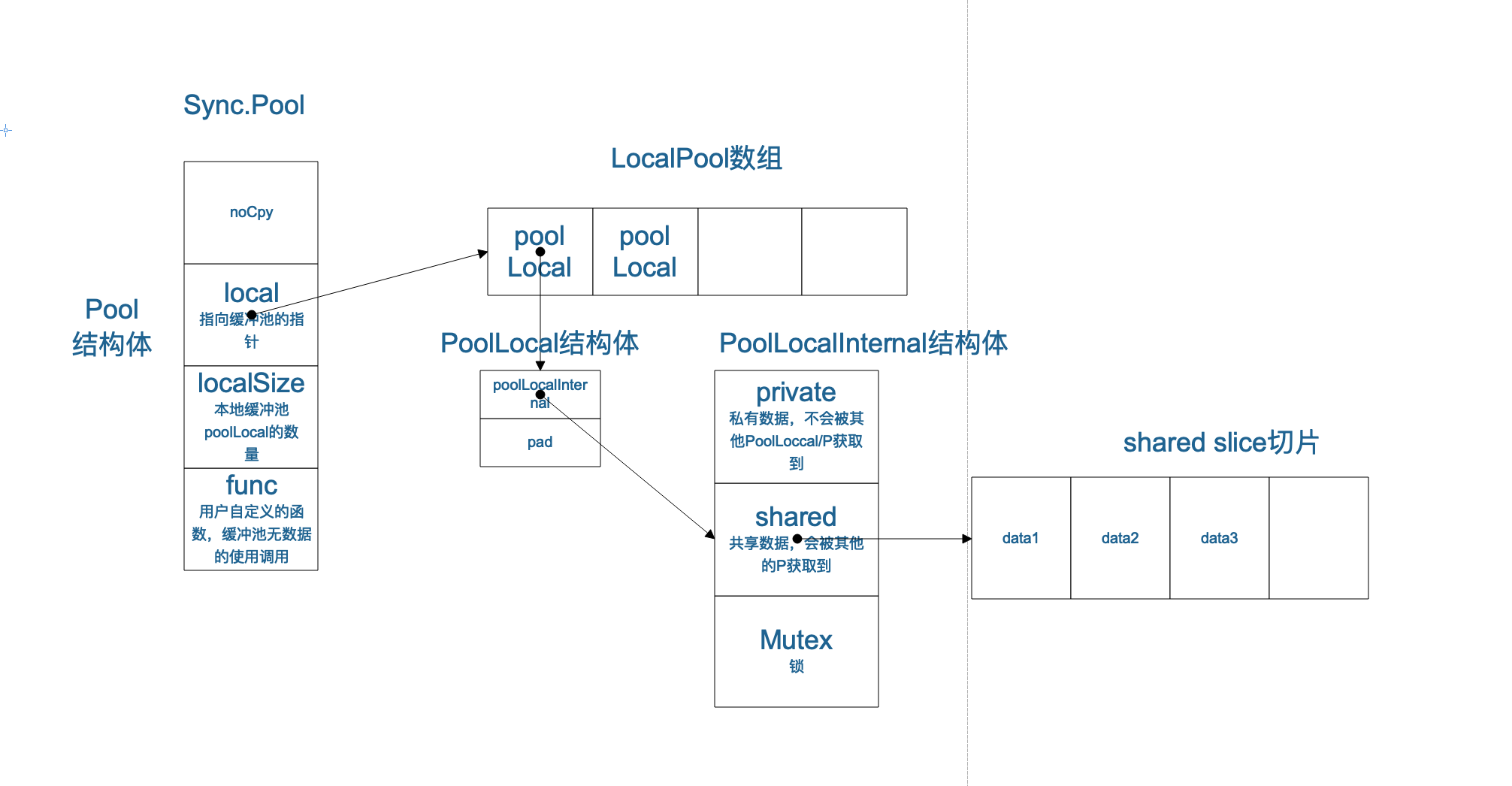
图片来源:A Brief Analysis of Golang Sync.Pool
sync.Pool 会在每个线程中维护一个 private 的 Pool(无锁),以及一个可以被其他线程 shared的 Pool(有锁),细节原理可以参考相关文档。在高并发场景下,它基本能够保证每个线程都能够获得一个线程私有的 RingBuffer 对象,从而不需要对其加锁。但 sync.Pool 有一个缺点是在 GC 时会被释放掉,此时会丢失缓冲区内的数据。不过由于我们的前提假设是高并发场景,故而可以推导出数据的丢失量较之于全局是微乎其微的。然而在低并发场景下,这种做法有可能导致缓冲区一直被 GC 清理掉而丧失大部分统计数据。
这里对 RingBuffer 做了一些简单的改动,当缓冲区写满后,会将数据交给驱逐器统计,然后清空缓冲区。
import (
"sync"
)
type ringStripe struct {
store []uint64
capacity uint64
}
func newRingStripe(capacity uint64) *ringStripe {
return &ringStripe{
store: make([]uint64, 0, capacity),
capacity: capacity,
}
}
func (s *ringStripe) PushOrReturn(item uint64) []uint64 {
s.store = append(s.store, item)
if uint64(len(s.store)) >= s.capacity {
ret := s.store[:]
s.store = make([]uint64, 0, s.capacity)
return ret
}
return nil
}
type ringBuffer struct {
stripes []*ringStripe
pool *sync.Pool
}
func newRingBuffer(capacity uint64) *ringBuffer {
return &ringBuffer{
pool: &sync.Pool{
New: func() interface{} {
return newRingStripe(capacity)
},
},
}
}
func (b *ringBuffer) PushOrReturn(item uint64) []uint64 {
stripe := b.pool.Get().(*ringStripe)
defer b.pool.Put(stripe)
got := stripe.PushOrReturn(item)
return got
}
设计
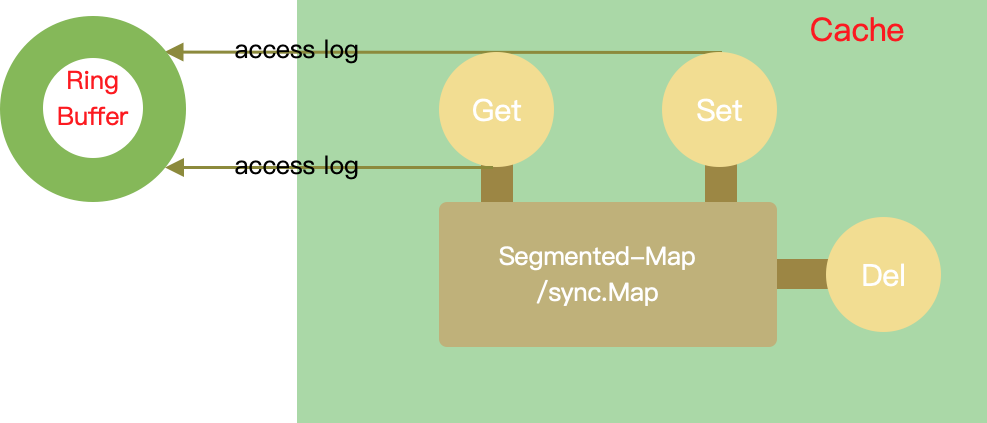
驱逐器
驱逐策略
通过不停读访问记录环形缓冲队列,我们能够拿到用户的访问记录。此时我们有两种驱逐策略:
- LRU(Least Recently Used) :最少最近使用,即维护一个数组,越靠前访问时间越近。
- LFU (Least Frequently Used):最少频率使用,即需要记录 Key 使用的频率,越低越容易被驱逐。
LRU 的问题在于,如果在某个数据在前9分钟访问了1万次,最近1分钟没有访问,那么依然会认为该 key 并不热门而有可能被驱逐。
LFU 的问题在于,经常会有一些数据在某时刻非常极其热门,但之后一直没人访问,例如因为某些原因被隐藏的用户动态这类场景。另外,LFU 的频率信息在缓存失效后依旧会存在内存中。
值得注意的一点是,缓存系统的驱逐往往是由于写入而引起的,换句话说,是为了在缓存中,给更加重要的 key 腾出空间,才驱逐出那些没它重要的 key。那么问题来了,无论是 LRU 还是 LFU 的写入过程中,都有一个假设是新来的 key 一定是更重要的,以至于我必须牺牲掉某个已有的 key。但这个假设很可能是不成立的。而且这种方式很容易导致一些冷门数据在短时间过热导致缓存系统迅速驱逐出了原先的那些热门数据。为了解决上述问题,于是就有了 TinyLFU。
TinyLFU 利用 LFU 作为写入过滤器,只有当新来的 key 的频率大于需要被驱逐的 key 时,此时才会执行写入,否则只进行频率信息的累加。也就是说所有新的 key 都会有一个被预热的过程才能够「够格」被写入缓存中。
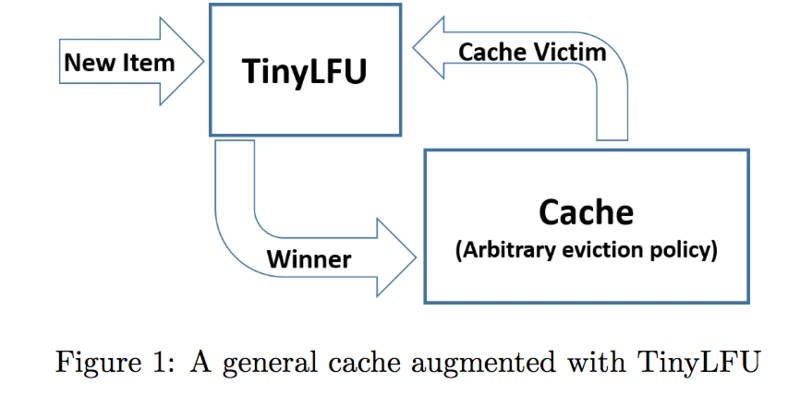
但此时会存在的一个问题是,当有突发性的稀疏流量(sparse bursts)进来时,他们会由于一直无法建立足够的频率使得自己被缓存系统而接纳,从而导致击穿了缓存。为了解决这个问题,于是又有了 W-TinyLFU。
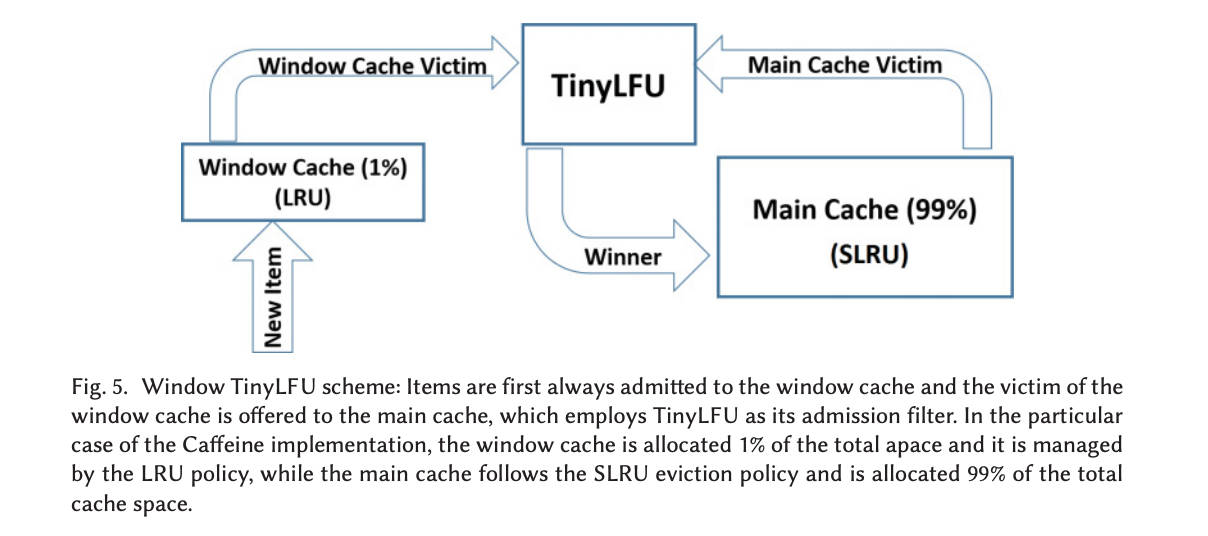
W-TinyLFU 算法吸收了上述算法的优点,在 TinyLFU 前面放了一个基于 LRU 的 Window Cache,从而可以使得前面提到的突发性稀疏流量会缓存在 Window Cache 里,只有在 Window Cache 里被淘汰的缓存才会过继给后面的 TinyLFU。至于最后的 Main Cache,虽然 W-TinyLFU 使用了分段式 LRU 来实现,但我们也可以根据实际情况修改使其符合我们需要的场景。
TinyLFU && W-TinyLFU 算法是由 Gil Einziger、Roy Friedman 和 Ben Manes 三人在 15 年共同写的论文:TinyLFU: A Highly Efficient Cache Admission Policy 所提出来的,后来 Ben Manes 还依照这个算法写了一个 Java 领域备受欢迎的缓存系统 Caffeine。
为了简化本文的实现,我们暂时先不实现 W-TinyLFU 算法(W-TinyLFU 的实现会另外写一篇文章介绍),而是实现一个简单的 LFU 驱逐策略。因此我们需要一个能够用来记录访问频率的数据结构。同时由于我们需要存储所有 key 的信息,所以还需要这个数据结构能够有效减少 key 的存储体积。
即便有了上面的频率计数器,为了找到那个需要被驱逐的 LFU key,我们似乎需要遍历所有 key。所以我们不得不再引入一个驱逐候选列表来帮助我们提前排序好需要驱逐的 key。
综上,我们还需要再实现:
- 能够有效压缩数据大小的频率计数器
- 预先排序的驱逐候选池
频率计数器:Count-Min Sketch
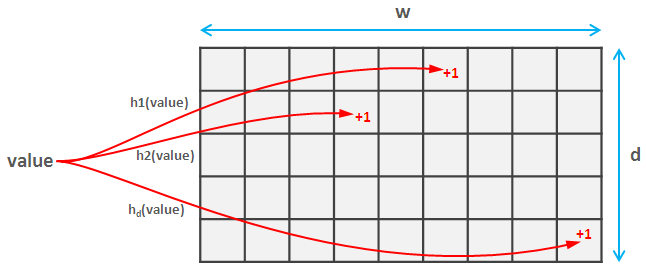
Count-Min 算法和布隆过滤器类似,核心思想还是通过将相同 Hash 值的数据共享同一份存储空间,以减小整体体积。h1~hd 代表不同的 Hash 算法,这里的 value 代表我们要存储的 key,横坐标表示 Hash 后的值,对哈希值对应每个网格进行 +1 操作。当需要计算某个 key 的估计值时,取对应所有网格数值的最小值。
为了避免一些短时间热度的 key 一直残留在缓存中,每隔一个时间间隔,还需要将所有网格计数器衰减一半。
设计
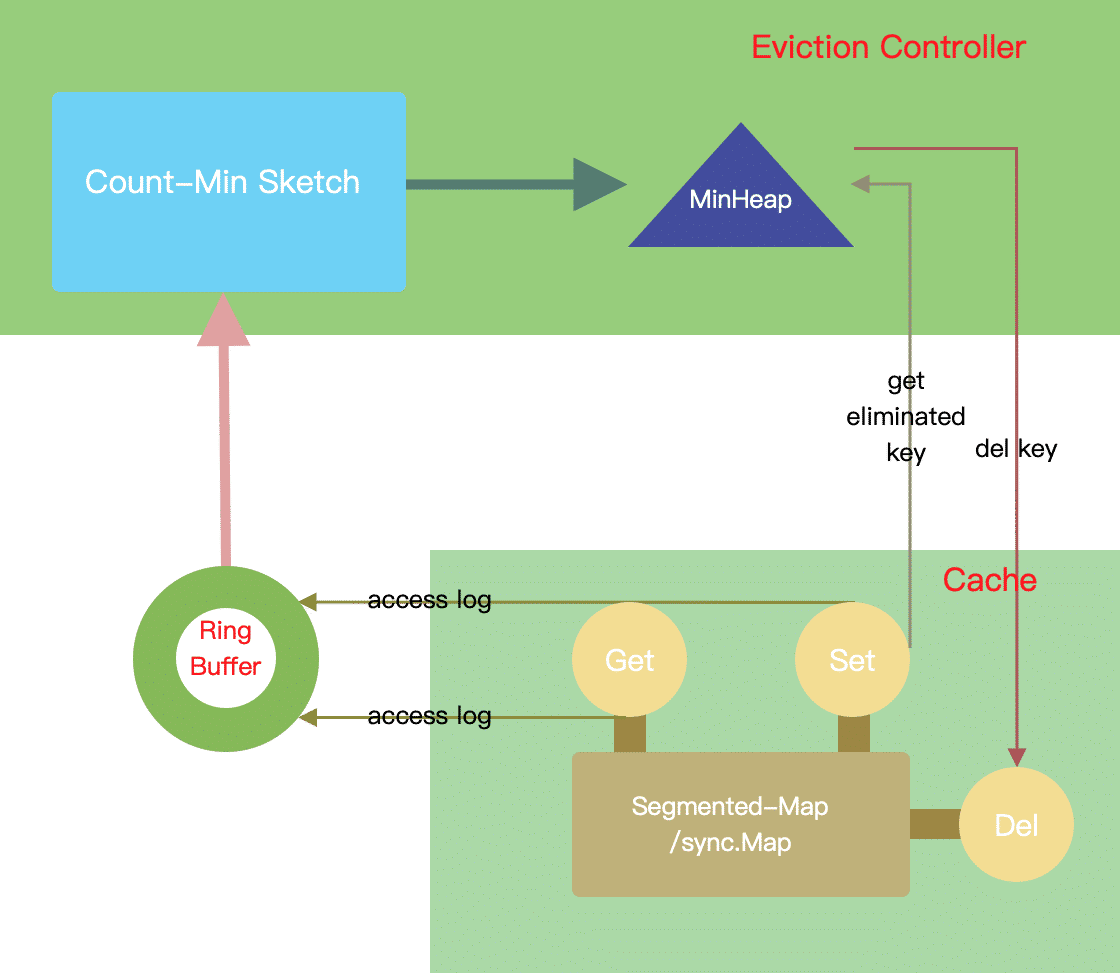
总结
经过一系列的步骤,我们终于实现了一个满足我们要求的现代内存缓存系统。可以看到,在缓存系统的设计中,对性能影响最大的是缓存的存储层,需要非常小心地进行锁的设计和优化。而对于缓存系统命中率影响最大,同时也是实现算法上最复杂的还是淘汰策略的选择。现代的许多内存缓存系统所选择的淘汰策略各有不同,许多都在现有的算法基础上做过一些自己的修改。即便一些缓存系统在 Benchmark 中非常优秀,但如果其测试数据访问模式与你的实际使用场景并不一致,它的数据对你的参考意义也并不大。所以依旧需要针对性地进行模拟压测才能够知道什么样的缓存系统适合你业务的场景。
参考资料