在 Linux 中,所有外部资源都以文件形式作为一个抽象视图,并提供一套统一的接口给应用程序调用。本文将以宏观视角试图阐述 Linux 中关于文件 IO 的整个调用脉络。
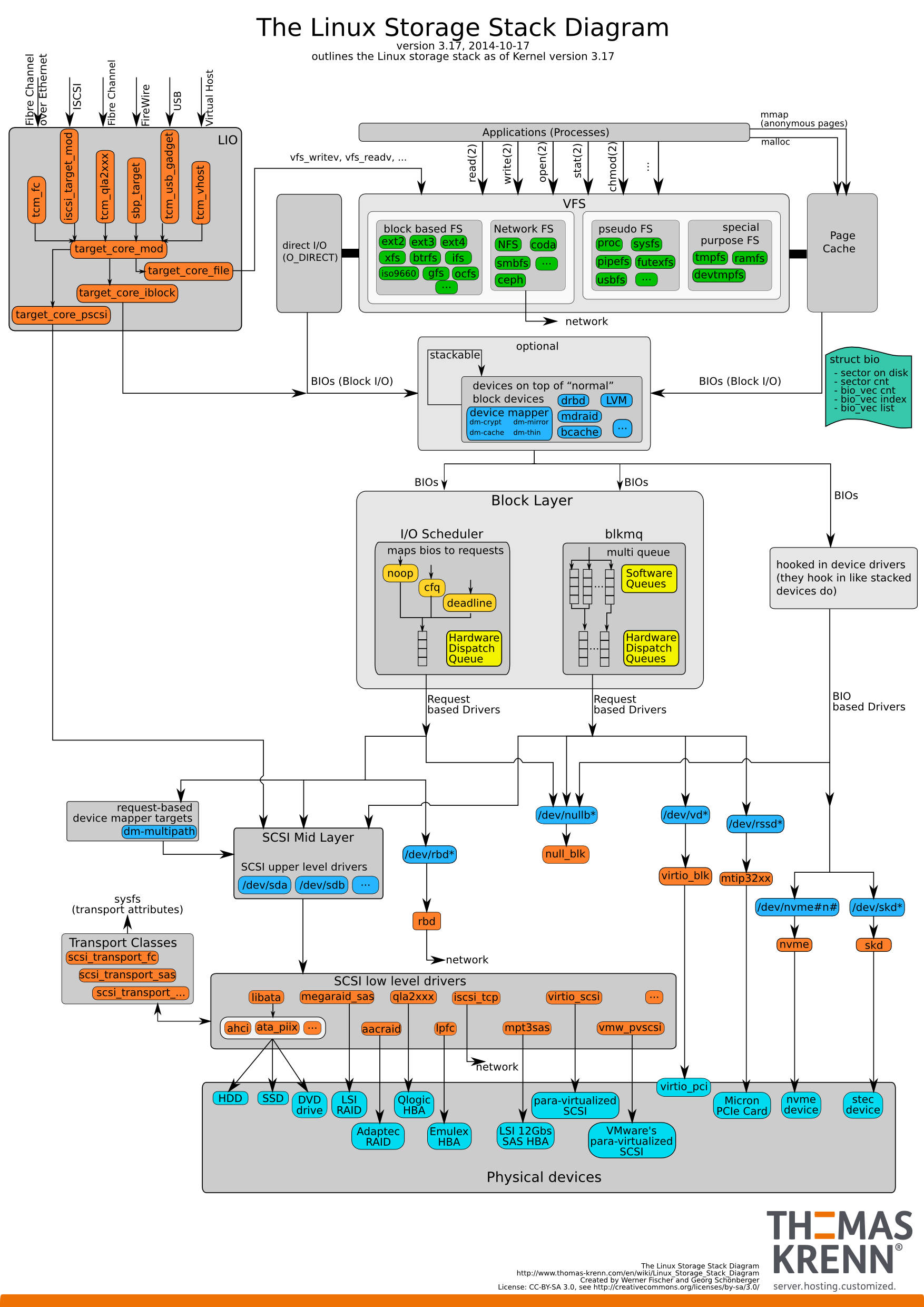
VFS
在 Linux 中,所有 IO 都必须先经由 VFS 层进行转发。通过 VFS 将包括磁盘、网络 Socket、打印机、管道等资源全部封装成统一的接口。
基础结构
VFS 自顶向下使用四个数据结构来描述文件:
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
struct mutex f_pos_lock;
loff_t f_pos;
}
struct dentry {
unsigned int d_flags;
seqcount_t d_seq;
struct hlist_bl_node d_hash; /* 哈希链表 */
struct dentry *d_parent; /* 父目录项 */
struct qstr d_name; /* 目录名 */
struct inode *d_inode; /* 对应的索引节点 */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op; /* dentry操作 */
struct super_block *d_sb; /* 文件的超级块对象 */
unsigned long d_time;
void *d_fsdata;
struct list_head d_lru; /* LRU list */
struct list_head d_child; /* child of parent list */
struct list_head d_subdirs; /* our children */
union {
struct hlist_node d_alias; /* inode alias list */
struct rcu_head d_rcu;
} d_u;
}
- inode: 索引节点对象,存在具体文件的一般信息,文件系统中的文件的唯一标识。
struct inode {
struct hlist_node i_hash; /* 散列表,用于快速查找inode */
struct list_head i_list; /* 相同状态索引节点链表 */
struct list_head i_sb_list; /* 文件系统中所有节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用计数 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用组id */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改时间 */
struct timespec i_ctime; /* 最后改变时间 */
const struct inode_operations *i_op; /* 索引节点操作函数 */
const struct file_operations *i_fop; /* 缺省的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
unsigned int i_flags; /* 文件系统标志 */
void *i_private; /* fs 私有指针 */
unsigned long i_state;
};
- superblock: 超级块对象,记录该文件系统的整体信息。在文件系统安装时建立,在文件系统卸载时删除。
链接
硬链接 VS 软链接:
- 硬链接为目标文件创建了一个新的 dentry,并将 dentry 写入父目录的数据中。
- 软链接创建了全新的文件,只不过它的数据保存的是另一个文件的路径,所以它有一个全新的 inode。
硬链接存在的文件必须实际存在,而软链接无所谓目标文件是否存在。
如果删除了原始文件的话,软链接会直接生效,但是硬链接依旧存在,因为 inode 的计数并没有变成0,所以对于硬链接而言,事实上原始文件并没有删除。

Page Cache
当 VFS 读取的 Page 不在 Cache 中时,先从外存读取数据并缓存进 Cache,再返回。之后当再读取同样的 Page 时,会先检查 Page Cache,如果已经存在,便不会再触发下层 IO。
当 VFS 试图写入 Page 时,除了写入外存以外,也会往 Cache 中写入新页。从而使得对新写入的页的读取可以不触发实际外存IO。正是由于这种性质,使得消息队列这类读写都集中在新数据上的应用,即便运行在 HDD 上也能够有惊人的读取性能。
当网络存储遇上 Page Cache
从 IO 层次图中我们可以发现,Page Cache 实现在 VFS 层,当读写都在本地时,的确不会出现问题。但当使用 NFS 这类网络存储时,远程进行的写操作并不能同步给本地,从而导致 Cache 无法被及时地 invalidate,导致读的还是老的数据。对于这种情况可以:
- 在 NFS 客户端处设置不缓存文件
- 调低目录属性缓存的最大时间 acdirmax
但如果存储的是不变的数据,例如归档的日志这类,在进行数据分析时,也能够充分利用 Page Cache 提供的缓存优势。
直接 IO
许多应用自身已经实现了缓存策略,此时操作系统自带的 Page Cache 可能会成了冗余。通过在打开文件时候设置 O_DIRECT 可以绕过 Page Cache,直接操作文件。
直接 IO 相比与默认方式减少了内存数据拷贝次数,降低了对 CPU 和内存带宽的使用,在数据量巨大的情况下,可以大大提升性能。
文件系统
文件系统是一种存储和组织数据的方法,使得用户对文件的访问、查找、管理变得更加容易。通过文件系统这一层抽象,隐藏了直接管理外存的复杂性。
下图展示了读取文件 /var/log/messages 的完整过程:

目前人们常用通用文件系统有 ext4 和 xfs。而在诸多细分领域,针对不同场景有非常多的新文件系统在近些年诞生。例如对于海量小文件(常见的图片、静态资源)的存储,有 FastDFS ,对 SSD 有专门优化的 JFFS2。FastDFS 通过在文件系统层把小文件合并成大文件,从而减轻大量小文件对系统的开销。而 JFFS2 通过把 data 和 metadata 在 SSD 上顺序存储,并使用 ouf-of-place 的方式更新,来减轻对 SSD 寿命的影响。
分区
文件系统自身作为一种软件实现并不一定100%可靠,虽然现代文件系统通过日志等技术已经极少出现系统故障,但即便如此,在使用文件系统的过程中,依旧会出现意外情况例如文件写满。通过文件系统的分区可以把故障限制在局部上,不至于造成全局性影响。
FUSE
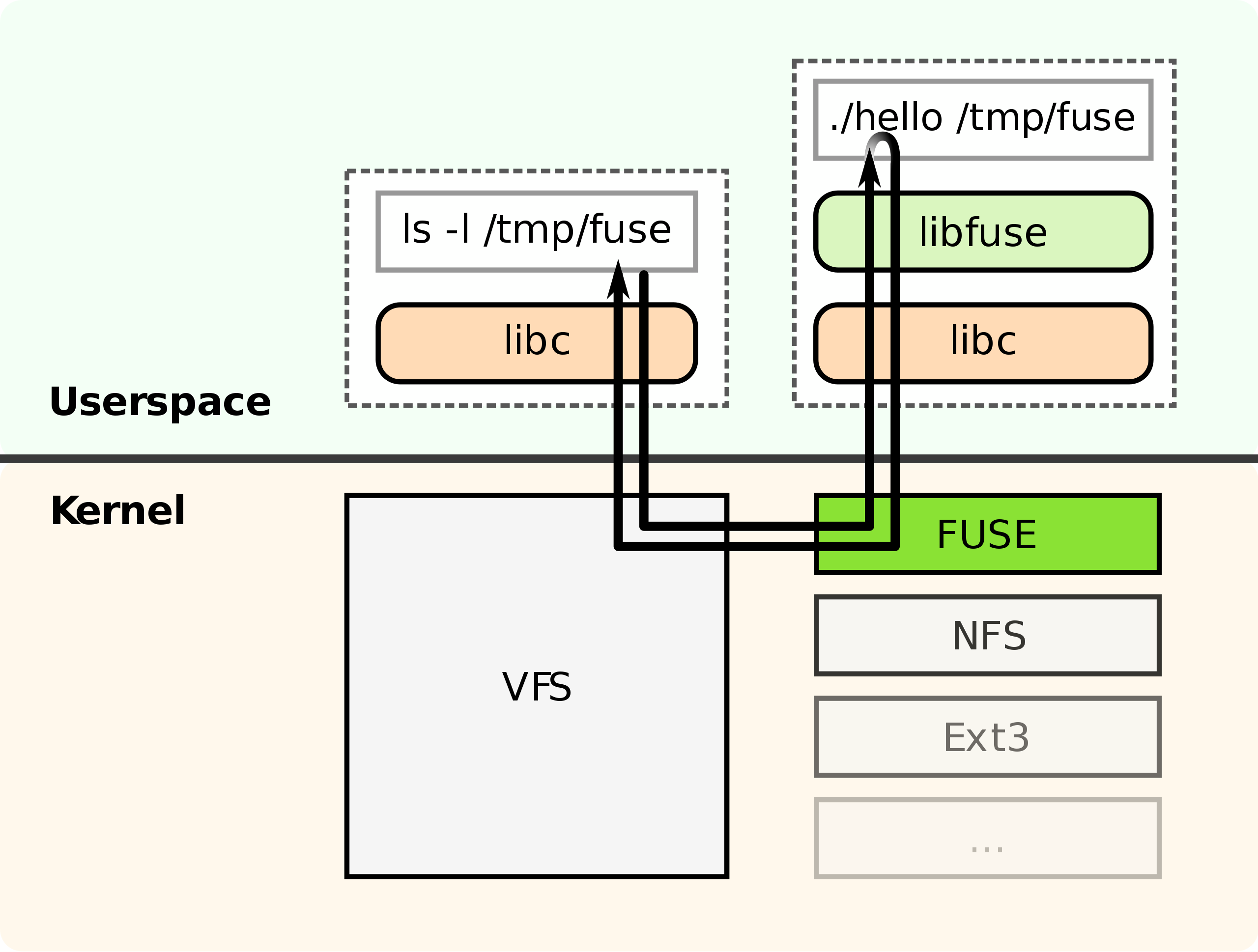
FUSE 全称 Filesystem in Userspace,是一个支持用户在用户态编写文件系统代码的内核模块,在 Linux 2.6.14 后开始支持。一般多用于分布式文件系统,例如 hdfs,ceph,s3fs 等。
由于 FUSE 极大地简化了文件系统的开发门槛,使得我们用数十行代码便能开发出一个文件系统,于是市面上出现了大量有趣的项目,例如 WikipediaFS,MysqlFS,TwitterFS,GitFS,GmailFS 等。
绕过文件系统读写裸设备
如果仔细观察文件系统的话,会发现它和数据库的部分功能十分类似,而对于数据库而言的话,由于其本身就实现了非常精细的数据组织方式,如果能够进一步接管掉文件系统的工作的话,可以有效地避免两个层级上一些重复工作的产生,从而更加高效地利用存储设备的性能。
于是许多数据库开始尝试了直接操作裸设备的方案,例如 Oracle 以及 Mysql。
通用块层
Linux下有两种基本的设备类型,一种是字符设备,另外一种是块设备。如果一个设备只能以字符流的方式被顺序访问的话,那么属于字符设备,例如打印机。否则则是块设备。Linux 通过通用块层封装了各类块设备的硬件特性,给上层提供了一个通用的抽象视图。
块(Block)是基本的数据传输单元,所以块大小不能小于存储设备的最小可寻址单元,同时由于 Page Cache 的存在,不能大于 Page 大小。
I/O 调度层
I/O 调度层管理块设备的请求队列,主要进行合并和排序进来的 IO 请求。合并 IO 是指对能够并成顺序访问的 IO 合并成一个 IO,以减少随机访问带来的影响。IO 排序主要针对 HDD 这类靠磁道寻址的设备,通过 IO 排序,可以减少寻址时间。