何为序列
对于计算机而言,一切数据皆为二进制序列。但编程人员为了以人类可读可控的形式处理这些二进制数据,于是发明了数据类型和结构的概念,数据类型用以标注一段二进制数据的解析方式,数据结构用以标注多段(连续/不连续)二进制数据的组织方式。
例如以下程序结构体:
type User struct {
Name string
Email string
}
Name 和 Email 分别表示两块独立(或连续,或不连续)的内存空间(数据),结构体变量本身也有一个内存地址。
在单进程中,我们可以通过分享该结构体地址来交换数据。但如果要将该数据通过网络传输给其他机器的进程,我们需要现将该 User 对象中不同的内存空间,编码成一段连续二进制表示,此即为「序列化」。而对端机器收到了该二进制流以后,还需要能够认出该数据为 User 对象,解析为程序内部表示,此即为「反序列化」。
序列化和反序列化,就是将同一份数据,在人的视角和机器的视角之间相互转换。
序列化过程
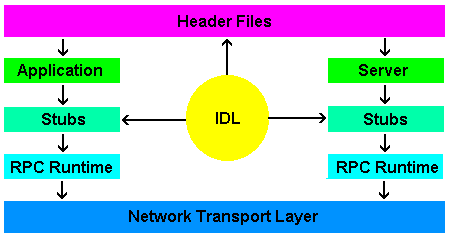
定义接口描述(IDL)
为了传递数据描述信息,同时也为了多人协作的规范,我们一般会将描述信息定义在一个由 IDL(Interface Description Languages) 编写的定义文件中,例如下面这个 Protobuf 的 IDL 定义:
message User {
string name = 1;
string email = 2;
}
生成 Stub 代码
无论使用什么样的序列化方法,最终的目的是要变成程序中里的一个对象,虽然序列化方法往往是语言无关的,但这段将内存空间与程序内部表示(如 struct/class)相绑定的过程却是语言相关的,所以很多序列化库才会需要提供对应的编译器,将 IDL 文件编译成目标语言的 Stub 代码。
Stub 代码内容一般分为两块:
- 类型结构体生成(即目标语言的 Struct[Golang]/Class[Java] )
- 序列化/反序列化代码生成(将二进制流与目标语言结构体相转换)
下面是一段 Thrift 生成的的序列化 Stub 代码:
type User struct {
Name string `thrift:"name,1" db:"name" json:"name"`
Email string `thrift:"email,2" db:"email" json:"email"`
}
//写入 User struct
func (p *User) Write(oprot thrift.TProtocol) error {
if err := oprot.WriteStructBegin("User"); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write struct begin error: ", p), err) }
if p != nil {
if err := p.writeField1(oprot); err != nil { return err }
if err := p.writeField2(oprot); err != nil { return err }
}
if err := oprot.WriteFieldStop(); err != nil {
return thrift.PrependError("write field stop error: ", err) }
if err := oprot.WriteStructEnd(); err != nil {
return thrift.PrependError("write struct stop error: ", err) }
return nil
}
// 写入 name 字段
func (p *User) writeField1(oprot thrift.TProtocol) (err error) {
if err := oprot.WriteFieldBegin("name", thrift.STRING, 1); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field begin error 1:name: ", p), err) }
if err := oprot.WriteString(string(p.Name)); err != nil {
return thrift.PrependError(fmt.Sprintf("%T.name (1) field write error: ", p), err) }
if err := oprot.WriteFieldEnd(); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field end error 1:name: ", p), err) }
return err
}
// 写入 email 字段
func (p *User) writeField2(oprot thrift.TProtocol) (err error) {
if err := oprot.WriteFieldBegin("email", thrift.STRING, 2); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field begin error 2:email: ", p), err) }
if err := oprot.WriteString(string(p.Email)); err != nil {
return thrift.PrependError(fmt.Sprintf("%T.email (2) field write error: ", p), err) }
if err := oprot.WriteFieldEnd(); err != nil {
return thrift.PrependError(fmt.Sprintf("%T write field end error 2:email: ", p), err) }
return err
}
可以看到,为了把 User 对象给序列化成二进制,它 hard code 了整个结构体在内存中的组织方式和顺序,并且分别对每个字段去做强制类型转换。如果我们新增了一个字段,就需要重新编译 Stub 代码并要求所有 Client 进行升级更新(当然不需要用到新字段可以不用更新)。反序列化的步骤也是类似。
上述这段冗长的代码还只是我们用于演示的一个最简单的消息结构,对于生产环境中的真实消息类型,这段 Stub 代码会更加复杂。
Stub 代码生成只是为了解决跨语言调用的问题,并不是必须项。如果你的调用方与被调用方都是同一种语言,且未来一定能够保证都是同一种语言,这种情况也会选择直接用目标语言去写 IDL 定义,跳过编译的步骤,例如 Thrift 里的 drift 项目就是利用 Java 直接去写定义文件:
@ThriftStruct
public class User
{
private final String name;
private final String email;
@ThriftConstructor
public User(String name, String email)
{
this.name = name;
this.email = email;
}
@ThriftField(1)
public String getName()
{
return name;
}
@ThriftField(2)
public String getEmail()
{
return email;
}
}
序列化问题
早在 1984 年提出 Remote Procedure Calls 概念时候,就基本定型了今天整个 RPC 的框架。后人所做的各式优化和改造,都是在这套框架下做各种 trade off,以解决不同场景下遇到的不同问题。
Stub 代码膨胀
从前面的 User �对象生成的 Stub 代码中我们已经感受到了这种针对于每个字段分别 hard code 处理产生的代码膨胀问题。在实际生产环境中,单个服务的 Stub 代码超过几万行也是非常常见的事情。虽然这种方式对服务性能并不会有影响,且也无需工程师做任何额外工作,但当项目非常庞大以后,会造成一些开发体验上的损失。比如 IDE 做语法分析速度会变慢,项目打开很卡。
Protobuf 在其官方实现中,使用的是反射来处理二进制与程序内部表示间的转换。
反射的本质是在语言层面提供了一种暴露程序现有类型和数据的能力,在运行时我们从二进制数据中解析到对应字段,然后通过反射获取到对应程序内结构体的 Field,并对其赋值。
这种做法显然会比硬编码的方式要慢得多,主要需要额外做以下事情:
- 查询当前类型信息
- 数据类型校验
所以通过反射来减少 Stub 代码量谈不上算是什么优化,只能说是在性能和便利性方面选择了便利性。同时也方便了 Protobuf 快速支持其他多种语言。
有意思的是,虽然 Protobuf 官方使用的是反射实现,但是有相当一部分人为了更高的性能,使用的是社区开源的 gogo/protobuf。下面是一段 gogo protobuf 编译后的代码:
func (m *User) MarshalToSizedBuffer(dAtA []byte) (int, error) {
i := len(dAtA)
_ = i
var l int
_ = l
if m.XXX_unrecognized != nil {
i -= len(m.XXX_unrecognized)
copy(dAtA[i:], m.XXX_unrecognized)
}
// 序列化 email 字段
if len(m.Email) > 0 {
i -= len(m.Email)
copy(dAtA[i:], m.Email)
i = encodeVarintUser(dAtA, i, uint64(len(m.Email)))
i--
dAtA[i] = 0x12
}
// 序列化 name 字段
if len(m.Name) > 0 {
i -= len(m.Name)
copy(dAtA[i:], m.Name)
i = encodeVarintUser(dAtA, i, uint64(len(m.Name)))
i--
dAtA[i] = 0xa
}
return len(dAtA) - i, nil
}
可以看到,gogo/protobuf 依然是在试图用硬编码来替换掉官方的反射实现,所以才能够提升性能。
减少数据传输大小
对于一般性的业务服务来说,CPU 资源会先于内存和网络成为一个系统的瓶颈。对于这类服务来说,时间往往比空间更加重要。但也有一些吞吐量极高,业务逻辑简单的服务(数据库/消息队列/…),网络带宽会优先于 CPU 能够制约服务性能的瓶颈,对于这类业务我们需要用时间换空间,压缩数据包体积。
编码压缩
在基本数据类型里,字符串的压缩方法已经有非常多常见的方案,并且往往是由业务方自己实现,所以这里不再赘述。除了字符串以外,主要就是一些数字类型:int32, int64, double。
假如现在我们有一个业务里有一个字段表示用户对某条消息的点赞数,对于大部分消息来说该值往往都很小,但因为极端情况的存在,我们依然需要使用 int32 类型,如果按照原始的二进制编码,无论值是多少都需要用 4 bytes 大小的空间占用。针对这种使用情况,常见的思想是,用一套编码约定,使得可以根据 int 值大小进行动态扩展编码长度。
Varint 编码
Varint 的思想很简单,每一个字节有 8 位,最高位表示下一个字节是否还是该数字的一部分,其余 7 位用原码补齐。例如:
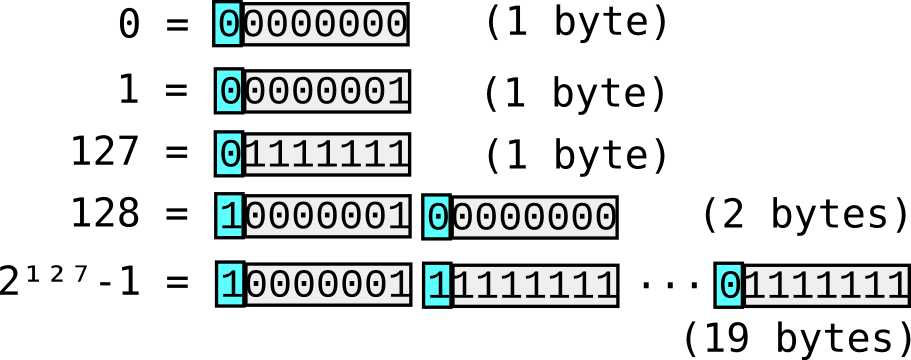
但是对于负数而言,最高位一定是 1,所以 varint 编码一定会变成 5 个字节,反而增加了大小。
ZigZag 编码
为了解决 varint 对负数不友好的问题,一种思想是把整个 int32 的空间映射到 uint32 的空间,编码只需要 uint32 中进行,最后做一层映射转换。ZigZag 就是使用的这个思想。
省略默认值
还有一类做法是通过双端共识,来减少一些默认值的传输。
例如一个字段 enable: bool 在 IDL 文件里定义的默认值为 true,如果我们当前数据包需要传输的值也是为 true,那就没有意义去传输这个字段。客户端收到数据包后,可以依赖 IDL 定义去还原出这个值。但是这个共识定义以后一般是不能变化的,否则会出现你以为你传的是 true,反序列化得到的却是 false 的结果。除非你能够做到同时让所有涉及到的参与方都更新里自己的 Stub 代码。
内存操作过多
影响序列化性能的另外一个问题是,在序列化过程中会频繁创建内存,一来这影响到了序列化速度,二来对于有 GC 的语言这也增加了垃圾回收压力。
我们先来看看序列化过程的内存申请与转换流程:
// === 序列化 ===
buf := make([]byte, 1024) //申请一段用户态缓冲区
||
||
Marshal(user, buf) //将 User 对象所有字段编码成二进制数据
- copy(buf[:], EncodeString(user.name))
- copy(buf[:], EncodeString(user.email))
||
||
io.Write(buf) //系统调用,从内核缓冲区将数据读入用户态缓冲区
// === 反序列化 ===
buf := make([]byte, 1024) //申请一段用户态缓冲区
||
||
io.Read(buf) //系统调用,从内核缓冲区将数据读入用户态缓冲区
||
||
Unmarshal(buf): User //根据编码格式,对二进制数据进行类型转换
- name := DecodeString(buf[:])
- email := DecodeString(buf[:])
在这个过程中,我们有以下几次内存操作:
- buf := make([]byte):每次解析都需要有一段独占的用户态缓冲区,用于从内核缓冲区读取数据。多次解析间可以重用。
- EncodeString/DecodeString:以 string 格式处理数据。由于这里的 buf 是会被重用的,所以这里并不能直接复用 buf 的内存,需要一次拷贝。如果该字段是一个非常大的 field,例如视频数据,这里的 copy 开销会非常巨大。
本文先不考虑如何优化内核态到用户态的拷贝,仅从序列化角度考虑如何减少用户态的拷贝。
避免大 string/bytes 类型的拷贝
在示例中,我们之所以不能直接使用 buf 内的数据,是因为这段数据还要被下一次序列化/反序列化重用。如果我们不再考虑重用,每个 buf 都是一次解析完整生命周期独占的,那么就可以直接赋值而不用拷贝。当然这种做法主要是针对于 string 和 bytes 类型(也只有这两种类型会出现超大不定长的内存占用),int/bool等其他基本类型在创建结构体时便已经申请了空间。
这块可以参考字节跳动在其 KiteX 中所实现的 Linkbuffer 结构。基本思路是每次解析前,先申请好一块 Buffer 地址(可以是其他解析过程释放的,也可以是新建的),然后整个生命周期都使用这一块地址。使用结束后释放(标记 free,并不释放内存) Buffer,然后可以交给下一次序列化使用。
预计算 Buffer 大小
在我们去做序列化前,我们便已经可以得知最终序列化完成时的 buffer 大小。甚至对于那些只含有基本定长数据类型的结构,我们甚至在编译时就能预知最终大小。对于这类能够事先知道体积的结构,我们在序列化前便可以创建一个固定长度的 buffer,从而让整个序列化过程只有一次 malloc。
直接操作 Buffer
序列化与反序列化是将二进制数据与程序内部表示直接相转换,才引起后面的那么多问题。一个更加直接解决问题的方式就是我们干脆就别序列化了,直接操作二进制。正所谓不解决问题,解决提出问题的人。
Protobuf V2 的作者从 Google 出来后,开发了 Cap’n Proto。有趣的是,后来 Google 自己内部又开源了 Flatbuffers。这两个项目基本思路是一样的,Stub 生成代码用以生成操作数据的接口,而这些接口底层不是在读写某个结构体,而是直接操作的最终序列化的二进制数据。这样序列化和反序列化相当于都在同一个二进制数据上进行,当然也就可以认为序列化时间为 0,性能可以超过任何序列化框架。
以下是 Cap’n Proto 生成的一段代码:
type User struct{ capnp.Struct }
func (s User) Name() (string, error) {
p, err := s.Struct.Ptr(0)
return p.Text(), err
}
func (s User) SetName(v string) error {
return s.Struct.SetText(0, v)
}
func (s User) Email() (string, error) {
p, err := s.Struct.Ptr(1)
return p.Text(), err
}
func (s User) SetEmail(v string) error {
return s.Struct.SetText(1, v)
}
以下是 Flatbuffers 生成的一段代码:
type User struct {
_tab flatbuffers.Table
}
func (rcv *User) Name() []byte {
o := flatbuffers.UOffsetT(rcv._tab.Offset(4))
if o != 0 {
return rcv._tab.ByteVector(o + rcv._tab.Pos)
}
return nil
}
func (rcv *User) Email() []byte {
o := flatbuffers.UOffsetT(rcv._tab.Offset(6))
if o != 0 {
return rcv._tab.ByteVector(o + rcv._tab.Pos)
}
return nil
}
func UserAddName(builder *flatbuffers.Builder, name flatbuffers.UOffsetT) {
builder.PrependUOffsetTSlot(0, flatbuffers.UOffsetT(name), 0)
}
func UserAddEmail(builder *flatbuffers.Builder, email flatbuffers.UOffsetT) {
builder.PrependUOffsetTSlot(1, flatbuffers.UOffsetT(email), 0)
}
可以看到两种方式生成的代码非常相似,并且生成的 User struct 没有像之前的序列化框架那样带上 Name 和 Email 字段,而是通过函数的方式读写能力。
我们前面说了,序列化本身的意义就在于提供人和机器视角对数据认识的一种转换。传统的思路是通过一个中间结构体,而这类方式是通过提供操作函数。
不过这类方式有一个通病就是仅仅只是提供了操作数据的能力,但是牺牲了程序编写者自己去管理数据的便利性。比如如果我们想知道这个 User 结构有哪些字段,除非序列化编译后的代码提供给了你这个能力,否则你将对一串二进制无从下手。比如你想直接把这个 User 对象和一些 ORM 工具组合存进数据库,你必须自己手写一个新的 User struct,然后挨个字段赋值。
这类序列化框架大多用在那些数据定义不怎么变化的核心基础设施服务,例如数据库,消息队列这类。如果用在日常业务开发,或许性价比不是很高。
最后
我们经常听到网上有人讨论,哪个序列化协议性能更好。其实如果我们真的认真去研究各类序列化方案,很容易会发现,序列化协议本身只是一份文档,它的性能优劣取决于你怎么去实现。不同语言实现,同语言不同方式方法的实现,都会对最终的易用性和性能产生巨大的影响。你完全可以把 Protobuf 的协议用 Flatbuffer 的方式去实现,能够提升非常多的性能,但未必就是你想要的。
与性能相比更为重要的是先弄清楚我们在序列化的各种问题中,希望解决哪些,愿意放弃哪些,有了明确的需求才能选择到适合的序列化方案,并且真的遇到问题时也能快速知道这个问题是否是可解的,如何解。