微服务之间的 RPC 调用往往会使用到限流功能,但是很多时候我们都是用很简单的限流策略,亦或是工程师拍脑袋定一个限流值。
这篇文章主要讨论在 RPC 限流中,当前存在的问题和可能的解决思路。
为什么需要限流
避免连锁崩溃
一个服务即便进行过压测,但当真实运行到线上时,其收到的请求流量以及能够负载的流量是不固定的,如果服务自身没有一个自我保护机制,当流量超过预计的负载后,会将这部分负载传递给该服务的下游,造成连锁反应甚至雪崩。
提供可靠的响应时间
服务调用方一般都设有超时时间,如果一个服务由于拥塞,导致响应时间都处于超时状态,那么即便服务最终正确提供了响应,对于 Client 来说也完全没有意义。
一个服务对于调用方提供的承诺既包含了响应的结果,也包含了响应的时间。限流能够让服务自身通过主动丢弃负载能力外的流量,以达到在额定负载能力下,依然能够维持有效的响应效率。
传统方案
漏斗
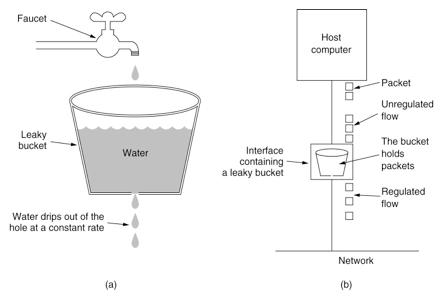
优点:
缺点:
令牌桶
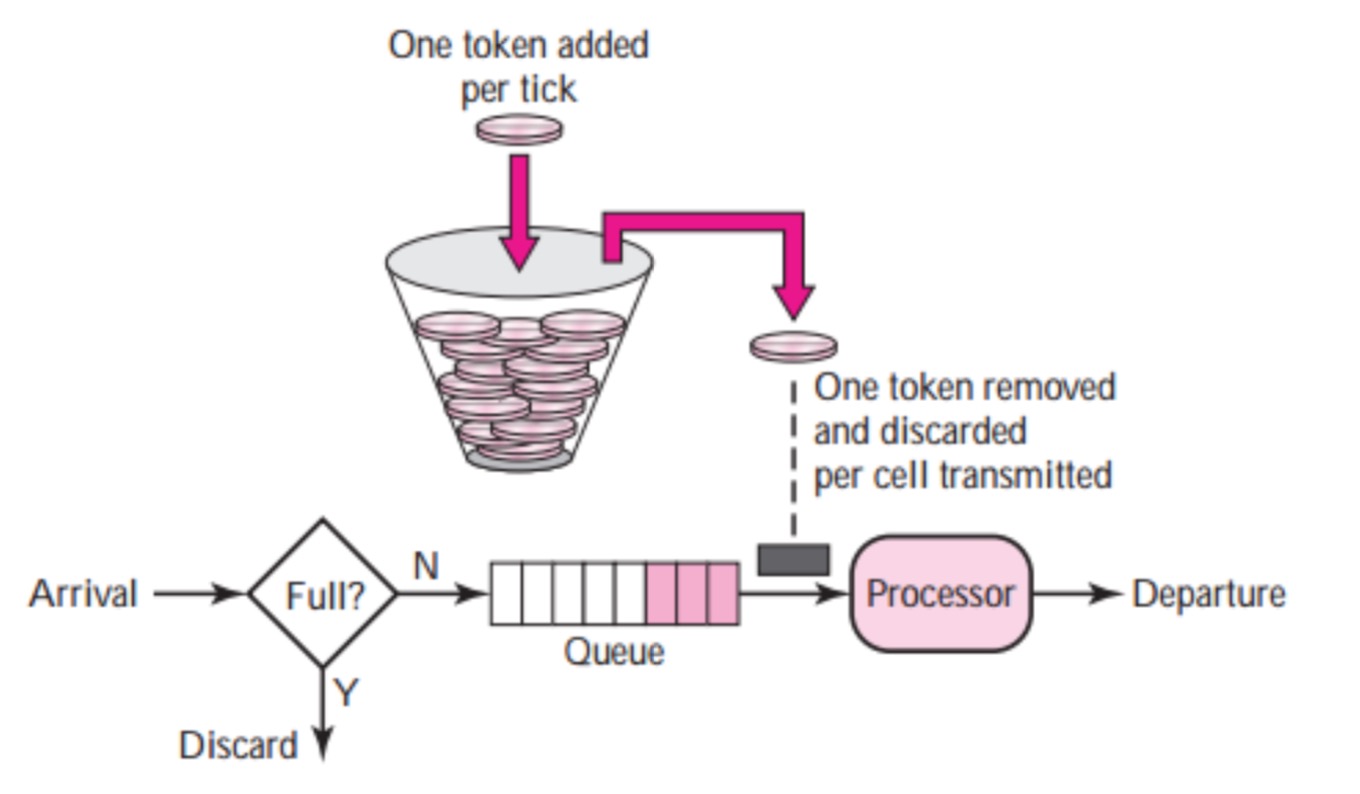
优点:
- 在统计上维持一个特定的平均速度
- 在局部允许短暂突发性流量通过
存在的问题
在两类传统方案中,都需要去指定一个固定值用以标明服务所能够接受的负载,但在现代的微服务架构中,一个服务的负载能力往往是会不断变化的,有以下几个常见的原因:
- 随着新增代码性能变化而变化
- 随着服务依赖的下游性能变化而变化
- 随着服务部署的机器(CPU/磁盘)性能变化而变化
- 随着服务部署的节点数变化而变化
- 随着业务需求变化而变化
- 随着一天时间段变化而变化
通过人工声明一个服务允许的负载值,即便这个值是维护在配置中心可以动态变化,但依然是不可持续维护的,况且该值具体设置多少也极度依赖于人的个人经验和判断。甚至人自身的小心思也会被带入到这个值的选择中,例如 Server 会保守估计自己的能力,Client 会过多声明自己的需求,长期以往会导致最终的人为设定值脱离了实际情况。
什么是服务负载
当我们向一个服务发起请求时,我们关心的无外乎两点:
并发请求数
对于 Server 而言,有几个指标常常容易搞混:
- 当前连接数
- 当前接受的请求数
- 当前正在并发处理的请求数
- QPS
连接数和请求数是 1:N 的关系。在现代 Server 的实现中,连接本身消耗的服务器资源已经非常少了(例如 Java Netty 实现,Go Net 实现等),而且一般对内网的服务而言,多路复用时,请求数变多也并不一定会导致连接数变多。
有些 Server 出于流量整形角度的考虑,并不一定会在收到请求以后,立马交给 Server 响应函数处理,而是先加入到一个队列中,等 Server 有闲置 Worker 后再去执行。所以这里就存在两类请求:接受的请求与正在处理的请求。
而 QPS 是一个统计指标,仅仅只表示每秒通过了多少请求。
在当下的时间点,对 Server 有负载起到决定性影响的,一般都是当前的并发请求数。
服务响应时间
当一个在线服务去响应一个请求时,其自身所做的工作抽象来看,无外乎以下两类:
- 计算:时间取决于 CPU 频率,固定值(不考虑超频)
- 等待:时间取决于当前并行请求数,不固定
- 排队等待 Server 有闲置线程/协程来响应请求
- 等待其他线程释放竞争资源(可能是锁,也可能占用的 CPU)
- 等待 IO(Storage, Network)返回 (不考虑下游抖动,该时间一般也为固定值)
从上面但分析我们可以看出,一个服务最终的响应时间:RT = 工作时间 + 等待时间。
负载能力估算
我们可以把一个微服务抽象为一个输入输出的水管,如下图所示:

中间的这根水管的“负载能力”其实就是这个水管的体积(管径 * 管长),这是一个非常好量化的指标。
我们的服务在线上所遇到的情况其实和这根水管是类似的,现在需要做的是找到一个类似计算水管体积的量化方法,来估算服务的负载能力。
现在我们在某一秒时间窗口内,对一个服务实例进行观测,很容易可以得到以下两个值:
- QPS:这一秒内的请求数,单位为 req/s 。
- AvgRT: 这一秒内的平均请求响应时间,单位 ms。
根据 Little’s law:
在一个稳定的系统(L)中,长期的平均顾客人数,等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W)。
该法则用于计算一个稳定且资源有限系统的吞吐量。
在我们的系统里,利用该法则,可以得到 Throughput = QPS * (AvgRT / 1000)。其中 AvgRt / 1000 将毫秒单位换算成秒。
从另一个角度去理解这个公式也可以认为,如果我们能够保证 Server 当前正在处理的请求量(inflight) 不超过该值,理论上每个请求的平均响应时间也应该维持在 AvgRt 左右(进水速度 ~= 出水速度)。这个最终算出来的量,就是我们想要得到的对于服务当前负载情况的估算值。而只有当服务开始出现负载压力以后,这个当前负载情况才可以被认为是负载能力。
Inflight,RT 与 Throughput 的关系
对于大部分在线服务来说,Inflight 和 RT 以及 Throughput 的关系有以下两个阶段:
- 在没有发生资源限制(CPU/磁盘/网络/内存)的情况下,随着 inflight 变大,RT 一般不会发生明显变化,Throughput 开始变大。
- 当 inflight 继续变大,出现了资源竞争时,RT 会随着 inflight 增大而增大,但 Throughput 并不会显著变化,因为有限的资源只能干有限的事情。
根据上面的这个现象,我们可以画出三个坐标图:
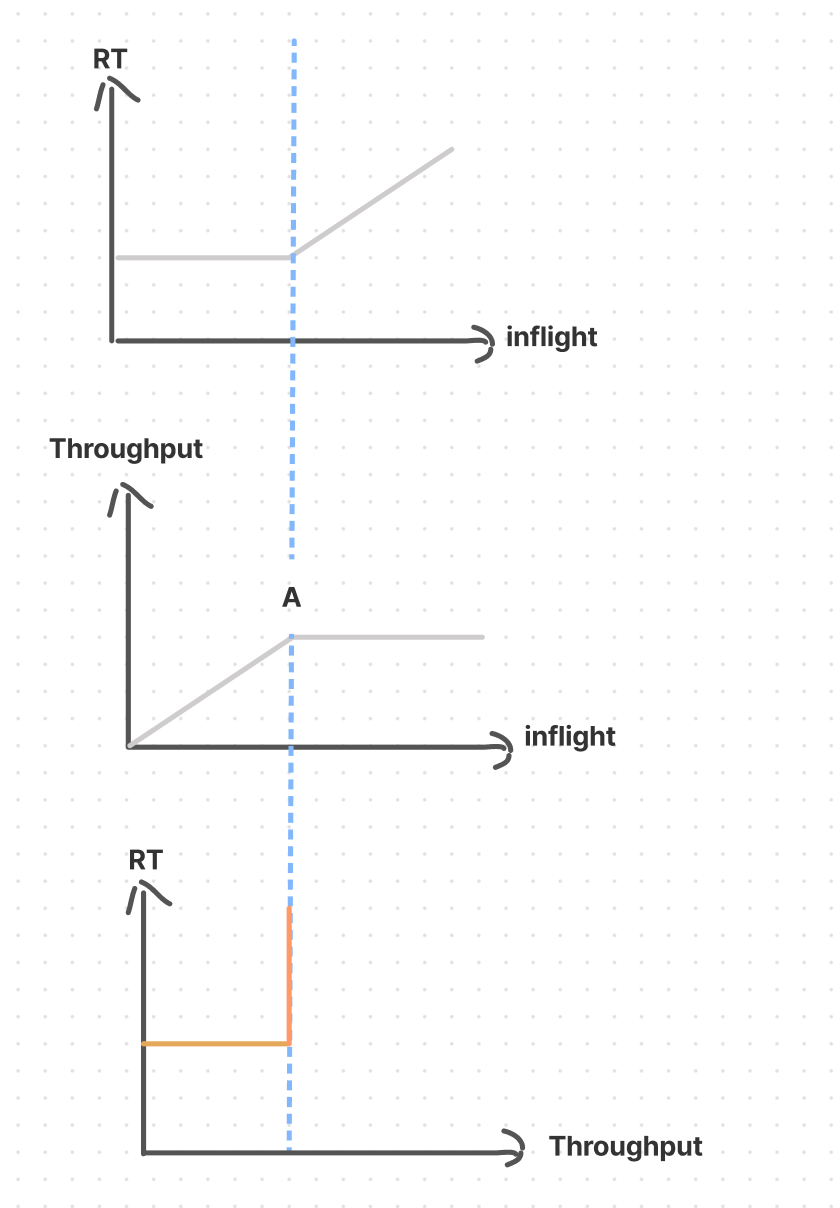
前两个图反应的是 Server 的实际现象,而第三个图,是将前两个图的相同的横坐标 inflight 消掉,单独看 RT 与 Throughput 的关系。第三个图表现了我们限流工作的本质:用 RT损失去换取吞吐量的提升。
更加符合实际情况的图是:
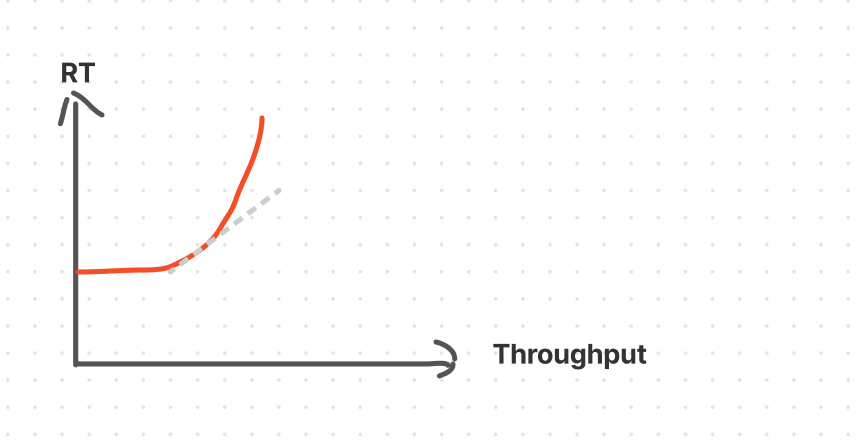
这里的斜率越低,代表这部分RT损失越划算。我们的限流策略,就是去找到这个最佳限流点。
工程实践
上述分析只是在一个理论模型上进行的一个推导,在实际工程应用中,需要考虑到以下现实情况。
何时启动限流
在一开始不存在资源竞争的阶段,我们没有任何必要去进行流控。所以需要一个启发指标来标志服务开始进入到来竞争的忙碌状态以触发流控逻辑,一般我们可以选择以下一些常见指标:
- OS Load1
- CPU Usage
- Avg RT 值
- Thread Number
- QPS
RT 的选择
前面已经推演得到了一个公式:RT = 工作时间 + 等待时间。而这里的 等待时间 还等于 排队时间 + 竞争时间。
但是 RT 只是一个单请求指标,要计算 Throughput 需要的是一个统计意义上的 RT 值,这时候选择是 AvgRt,还是 MinRT,还是 P95RT 就是一个细节但极为重要的事情了。
如果我们是一个性能极为稳定的系统,类似交换机,路由器这类,那么包与包之间不会彼此互相影响,所以这类系统的 RT = 工作时间 + 排队时间。而我们希望尽可能减少排队时间(因为没必要,大家都去排队会造成更加拥挤),所以这类情况 RT 可以选择使用 MinRt,因为 MinRT 最接近固定时间。这也是 Google BBR 算法所使用的值。
但是业务服务的不同之处在于,请求与请求之间不仅会争抢 CPU,存储,也可能出现类似锁竞争的问题。这部分问题导致竞争等待时间非常不确定,抖动频繁且不可预计。如果依然使用 MinRT,会导致低估了服务的并发能力。
一个例子可以更加直观感受这个过程:某大学每年招收1000研究生,2年学制,但考试太难,导致平均3年才能毕业。这个时候去计算该大学同时能够容纳多少研究生,如果取2年,显然不合适。
但是不是意味着我们就可以直接用 AvgRT 呢?其实也不是,限流很难做到刚好卡在一个精确的点上,就算真的卡精确了,也会导致容错性不高。所以限流会倾向于略微低估系统的负载能力。Bilibili 在他们公开的微服务框架 Kratos 中,使用的是对每一个采样窗口中的 AvgRT 中取最小的那个 AvgRT。而阿里的 Sentinel 使用的是真正意义的最小 RT。
当根据实际业务特性选定好了 RT 指标后,再乘以前面统计到的 QPS 则可得到 Throughput 值,此时只要判断当 Inflight > Throughput 直接丢弃便可实现一个自适应且有科学度量标准的限流策略。