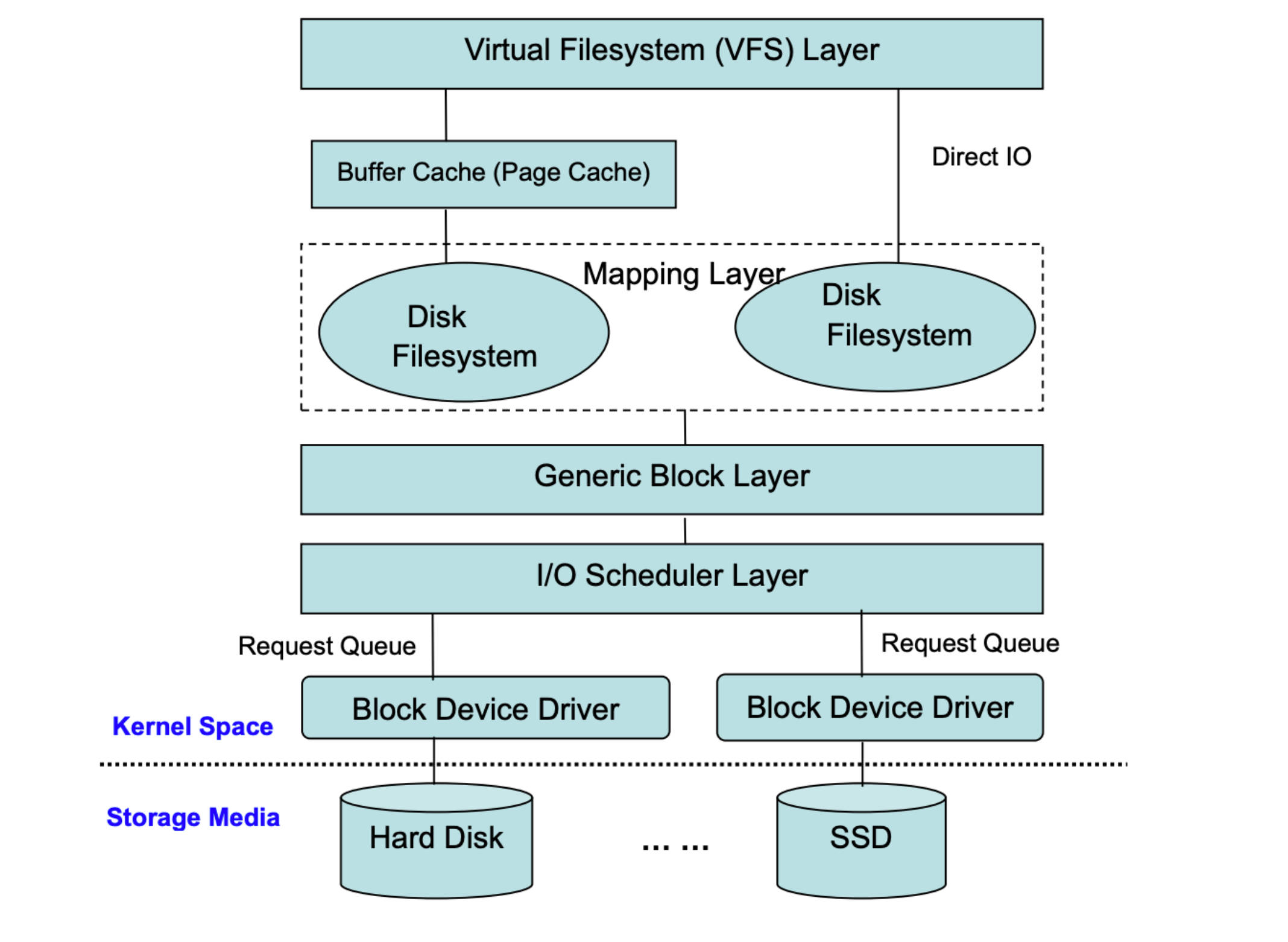
文件系统是操作系统 IO 栈里非常重要的一个中间层,其存在的意义是为了让上层应用程序有一层更加符合人类直觉的抽象来进行文档的读写,而无需考虑底层存储上的细节。
本地文件系统
在讨论分布式文件系统前,我们先来回顾下本地文件系统的组成。
存储结构
在前面一张图里,我们能够看到文件系统直接和通用块层进行交互,无论底层存储介质是磁盘还是 SSD,都被该层抽象为 Block 的概念。文件系统在初始化时,会先在挂载的块存储上的第一个位置创建一个 Super Block:
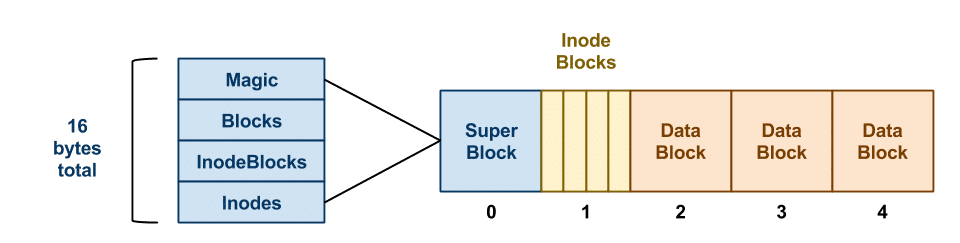
上图右边部分就是一块完整的存储,可以将其想象成一个数组。
Super Block 中存储了该文件系统的信息,其组成部分如下:
- Magic:
MAGIC_NUMBER or 0xf0f03410 ,用来告诉操作系统该磁盘是否已经拥有了一个有效的文件系统。 - Blocks: blocks 总数
- InodeBlocks: 其中属于 inode 的 block 数
- Inodes: 在 InodeBlocks 中存在多少个 inodes
由于这里的 Blocks 总数、InodeBlocks 总数、每个 Block 的大小在文件系统创建时就已经固定,所以一般来说一个文件系统能够创建的文件数量在一开始就已经固定了。
Linux 中每个文件都拥有一个唯一的 Inode,其结构如下:
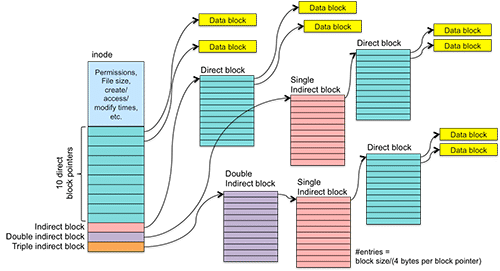
inode 上半部分的 meta data 很容易理解,下半部分的 block 指针的含义分别为:
- direct block pointer: 直接指向 data block 的地址
- indirect block: 指向 direct block
- double indirect block: 指向 indirect block
- triple indirect block: 指向 double indirect block
由于一个 inode 大小固定,所以这里的 block pointers 数量也是固定的,进而单个文件能够占用的 data block 大小也是固定的,所以一般文件系统都会存在最大支持的文件大小。
我们以 ext3 文件系统为例,其 superblock 定义 中有 12 个 direct block pointers,1 个 indirect block,1 个 double indirect block,1 个 triple indirect block( ext3/ext4 相同)。假设一个 block pointers 的大小为 4 bytes,则单个文件 inode 能够存储的最大 data blocks 大小(即最大文件大小)为:
(12 + (block_size_bytes/4)^1 + (block_size_bytes/4)^2 + (block_size_bytes/4)^3) * block_size_bytes
当 block_size_bytes == 1024 时,最大文件大小为 16 GiB。但当 block_size_bytes == 4096 时,虽然上述公式值为 4 TiB,但由于 ext3 文件系统对单个 inode 上的 blocks 数量i_blocks 的类型为 __le32 即 __u32 ,所以单个文件的 blocks 数不能 > 2^32-1 个,且这里 i_blocks 表示的 block 指的是扇区而非前面说得逻辑块,其大小被固定为 512 bytes,所以文件大小不能 > 512 * (2^32 - 1) ,即约等于2 TiB。扇区是过去磁盘时代的概念,在 SSD 中虽然不存在扇区的概念,但为了兼容旧软件生态,它会提供一个假的扇区值,一般为 4KB。但由于 ext3 该值是写死在代码中的,所以即便是 SSD 也存在该限制。
分布式文件系统的演化
如果我们希望用户对文件的读写操作都通过网络进行而不是本地,以实现多台机器间共享文件状态,通过图1的 IO 流程不难发现,我们只要在文件系统层将其 IO 操作转发给网络上的存储节点而不是本地通用块层,我们就能在应用程序无感知的情况下实现一个分布式文件系统。
结合之前的本地文件系统流程,我们可以把分布式文件系统中的数据访问模式分为两步:
- 检索文件 Metadata (在本地文件系统中即 inode ),找出文件内容存放地址 (小文件)
- 根据地址读取文件内容 (小文件/大文件)
下文介绍的所有分布式文件系统也都是在这两步上做主要取舍和优化,以适应不同应用场景。
GFS
GFS 是 google 最早为解决其爬虫抓取的网页文件过多而设计的分布式文件系统。
架构相似的文件系统还有:
- HDFS(开源版实现)
- TFS: Taobao FileSystem
设计目标
GFS 的设计目标是:
- 容忍机器/磁盘故障 (component failures are the norm)
- 面向大文件设计 (Multi-GB files are common)
- 适用于 append 多于 overwrite 的场景
架构
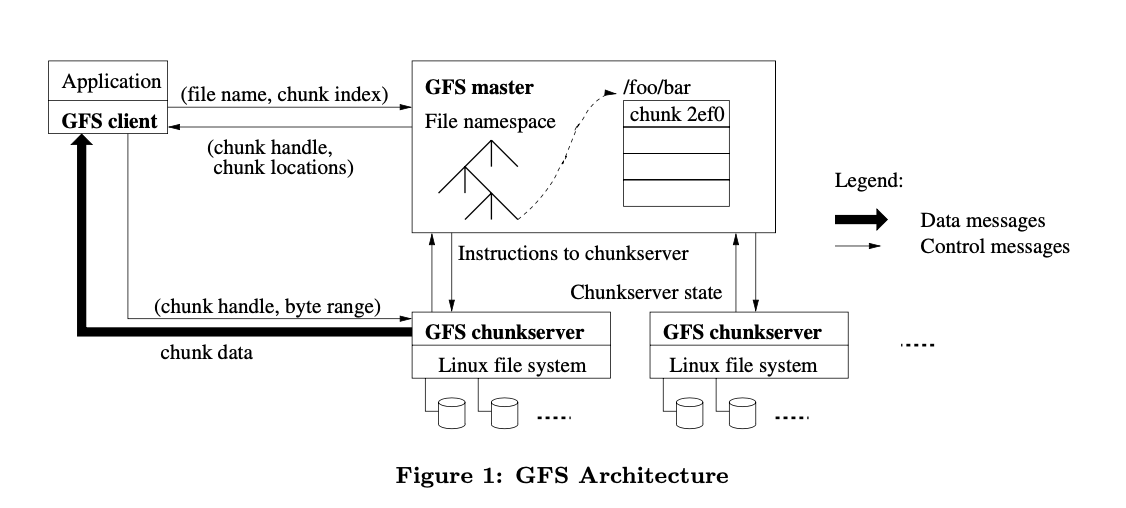
从上图我们可以看出 GFS 的设计思路:
对于读请求:
- Client 先向 master 节点请求 (filename, chunk index) 元组对应的 (chunk handle, chunk locations)
- 再向 chuckserver 请求 (chunk handle, byte range)
- chunkserver 返回给 client chuck data
由于设计目标是大文件场景,所以 client 端不会缓存 chunk data,但是会缓存 metadata。而对于 chuckserver 而言,其文件缓存利用了 Linux 自带的 buffer cache。
对于写请求:
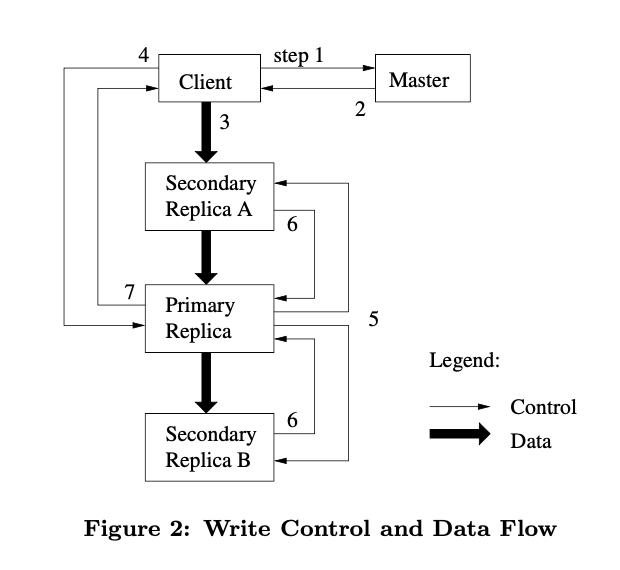
- client 向 Master 请求持有 lease 的 chunk(primary replica)位置和其他 replicas 的位置
- Master 返回位置信息,client 将这些信息缓存起来
- client 将数据发送到所有的 replicas,每个 chunkserver 会把数据存在 LRU 缓存中
- 在所有的 replicas 都收到了数据之后,client 会向 primary 发送写请求。
- primary 会首先给该写入操作分配一个编号,确保所有写入操作都有一个唯一的顺序,且该顺序在所有 secondaries 上也是一致的。然后给 secondaries 发送写请求。
- secondaries 告知 primary 操作执行完毕
- primary 向 client 应答,期间的错误也会发送给 client
一致性保证
对于 metadata 的信息修改一定是一致的,因为 master 是一个单一主节点架构。但对于chuckserver上的写操作在不同情况下有不同的表现:

上图名词的解释:
Write 表示 overwrite 类型的写,即指定在 [offset, bytes_length + offset] 范围内的写入操作。而 Append 表示追加类型的写,不需要指定 offset 可直接执行写入。
defined 表示写完以后再读,读到的一定是写的内容的定义结果,undefined 表示未定义行为
consistent 表示多个副本的内容是一致的
对于 overwrite 类型的写入来说:
- 顺序写时,毫无疑问可以得到确定的结果和一致性。
- 并发写时,不同的执行顺序会产生不同的结果,而执行顺序完全取决于 primary 收到请求的前后,所以对于每个 client 来说,并不能保证操作成功后的结果就是自己刚才的写入。但是由于 primary 在决定顺序,所以每个副本本身数据还是一致的。但如果并发写时,某个 secondary 写入失败了,那么就会产生副本不一致的情况,此时需要客户端自己处理这类错误,重新发起写入请求,直到成功。GFS 自身并不保证这种情况的一致性。
对于 append 类型的写入来说:
无论是顺序写入还是并发写入,都会遇到中间某个操作执行失败的情况,此时都会需要客户端重试。
append 操作并不是幂等的,所以在失败重试的时候,会在上一步执行结果基础上进行追加,导致上一个没有执行成功的副本数据出现一个断层(对于断层直接填充空值):
writes:
1. append 1
2. append 2(failed in chunkserver2)
3. append 2(retry)
==>
chuckserver1 (primary)
1,2,2
chunkserver2 (secondary)
1,*,2
对于上述情况,chuckserver1 和 chuckserver2 虽然在中间位置的数据不一致,但重试成功后,数据依然都写入了(at least once),所以依旧是定义行为。而这种数据不一致的情况,需要客户端自己事先知晓,且在客户端侧进行数据重复的处理(在 SDK 层做统一过滤)。
从上述描述中我们不难发现,GFS 的实现奉行「重客户端轻服务端」思想,把许多原先需要服务端做的校验和保证都交由客户端实现,服务端只做最基本的工作,这种设计思想可以让服务端的实现更加简洁和稳定。
缺陷
- 一个小文件可能会被分配到单一个 chuck 上,从而导致出现读写的热点。
- 大量小文件的读写成了随机读写,性能很差
- 设计假设是通过增大 chunk 的 size 从而降低文件数目大小,以减轻 master 节点的负载压力,但实际情况依旧会最终出现文件数目过大的情况。
- master 的单点架构容易让 master 自身成为瓶颈
- 应用层的一致性保证较差,需要客户端做太多判断
Colossus: GFS 2.0
由于后来 Google 内部随着规模越来越大,单点的 master 也逐渐支撑不住巨大的集群规模,Google 又研发了新的 Colossus File System。但关于该系统的设计还未公开,网上介绍并不多,这里只从能够找到的资料里来一探究竟。
架构
Colossus 的设计思路是:
- 水平扩展:重新设计 Metadata 的数据结构,使 Master 节点扩展成一个分布式的架构
- 垂直嵌套:让同一架构垂直嵌套以实现更大的扩展能力
从本地文件系统中的 inode 设计我们可以看到,对于 Metadata 我们是以一颗树的方式在进行存储的,而树这种数据结构是不太容易进行拆分以实现分布式的。所以第一步是将树的结构变成一个 key-value 的结构:
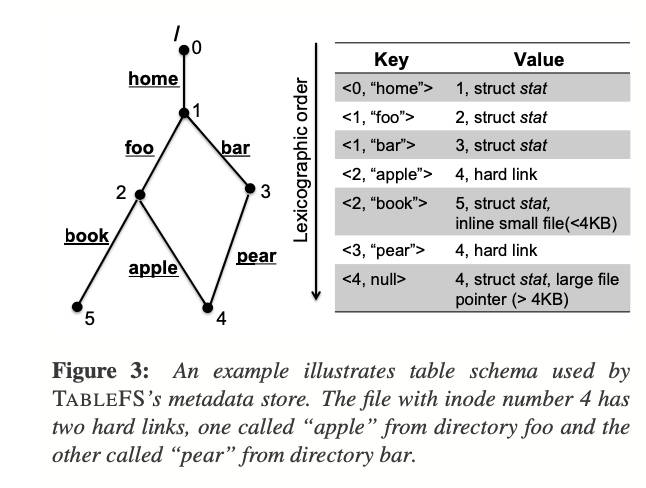
对于 key-value 结构,有非常多的数据结构可以选择,例如 LSM Tree,而且这些结构都可以非常易于进行分布式管理。而对于 Google 来说,现成的 Key-Value 存储就是 BigTable。但问题是 BigTable 的实现其实是基于分布式文件系统也就是之前的 GFS 的。这就导致了一个循环依赖问题。
所幸的是,对于文件系统的 Metadata 存储而言,有一个非常独特的特性,那就是「规模递减」。例如:
FileSystem(1000 TiB)
==> Metadata(10 TiB) + Chunk(990 Tib)
---
Metadata(10 TiB) ==> FileSystem(10 Tib) = Metadata(0.1 Tib) + Chunk(9.9 Tib)
---
...
即根据:
- FileSystem(X Tib) = Metadata(0.01X Tib) + Chunk(0.99X Tib)
- Metadata(Y Tib) = FileSystem(Y Tib)
所以:
FileSystem(X Tib) = FileSystem(0.01X Tib) + Chunk(0.99X Tib)
由此我们发现一个大的文件系统一定能够由一个更小的文件系统加上 ChunkServer 集群搭建起来,这也是 Colossus 设计的核心思想。而规模被层层缩小到最后时,我们就可以将其用一个最简单的强一致的分布式存储系统来作为最后的 BigTable 的存储系统,例如 Chubby。
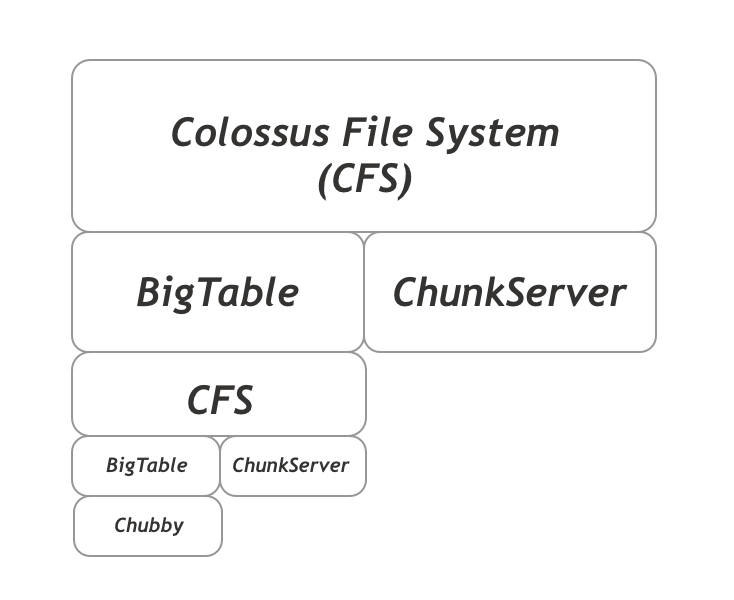
前面我们已经将 Metadata 数据变成了 Key-Value 结构,并且这里的 BIgTable 底层数据结构为 LSM Tree。而 LSM Tree 的特点就是将数据的写操作都转换为了顺序写入,从而大大提升了写的性能。而我们 GFS 那边又讲了,对于一个大文件的顺序写入,只有在跨越(创建)了新的chunk时,我们才需要和 Master 节点进行通信,所以这里落在 BigTable 上的读写请求其实是非常少的,从而也进一步降低了对最底层 Chubby 的压力。我们这里用一个推导过程来解释这个架构的强大之处:
- W(x,y) 表示 client 端的写入
- M(x,y) 表示 Metadata 节点(即 BigTable)的写入次数
- C(x) 表示 ChunkServer 的写入次数
- 上面的 x 表示写入次数,y 表示每次写入大小
- chunk 块大小为 B
- 单条 Chunk 的 Metadata 大小为 m
W(N,S) => M(N*S/B,m) + C(N)
M(N*S/B,m)=W(N*S/B,m)=> M(N*S/B*m/B) + C(N*S/B)
...
从上述推导可以看出,架构嵌套层数越深,最终 Metadata 节点的写入会越来越小。
Haystack: Design for small files
上面说的 Google 的两代文件系统都不是专门为小文件而设计的,为解决小文件的需求,Facebook 内部研发了 Haystack 。
在看 Haystack 的架构前,我们可以先看看之前的架构对小文件会产生哪些影响:
- 大量小文件产生了大量的 chunk,这些 chunk file 本身也会占用本地文件系统的 metadata。从而导致无论是上层分布式文件系统还是底层机器上的文件系统都产生了海量的 Metadata 数据。甚至可能 Metadata 数量量比实际文件内容数据量还大。
- 底层机器的本地文件系统大多不适合对海量小文件进行检索。
- 访问模式为大量随机读写,大大拖慢了 IO 性能。
从上描述我们可以发现,在小文件的场景中,本地文件系统成了非常大的一个瓶颈所在。而 Haystack 的设计最大胆的地方就是直接去掉了本地文件系统,直接和块存储通信。
另外只要我们还是随机读写,无论怎么进行架构设计,都无法解决随机读写 IO 性能差的问题,所以我们需要想办法将随机读写转换为顺序读写。
由此我们就能够大致理解 Haystack 的设计方向了。
架构
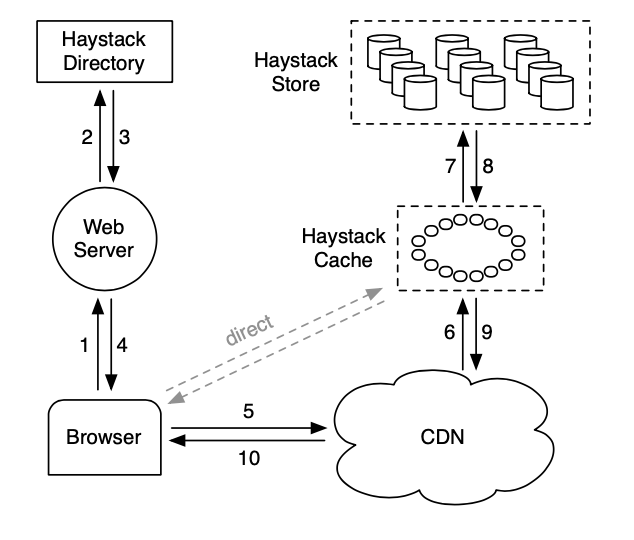
Haystack Directory
即 GFS 中的 Master 节点,管理 Metadata 信息。
Hystack Cache
缓存内部请求的文件,用来缓解热点问题。
Hystack Store
由于 Hystack 已经去掉了文件系统,所以这里把整个 Volume 当作一个大文件来处理。
Store 中存在两种大文件:
Store File

每个文件对象为一个 Needle 。
Index File

每个文件对象会对应在 Index File 中创建一个 Needle,其中包含了该文件在 Store File 中的 Offset 信息。更新操作只需要更新 Index File 并在 Store File 中 Append 新的一个 Needle 就行。删除操作也仅仅只需要将索引的 Flag 标记为删除。这些操作产生的脏数据都可以后续异步回收程序进行重整处理。
Index File 可以被完全加载到内存,故而能够大大加快检索效率。一次文件的读取最多也只会在 Store File 侧产生一次 IO 操作。为了实现这点,Haystack 也做了非常多的索引压缩以降低内存占用。
JuiceFS: Cloud Native Solution
上面讲的文件系统都是基于私有云的,事实上在现在的公有云架构上,有很多事情已经开始发生了变化,以 AWS 举例:
- EBS/S3 已经实现了副本策略
- EBS/S3 本身就保证了高可用
而在面向传统私有机房的架构设计中,上述两点是完全不能保障的,以至于有一句很著名的话叫做,硬盘不是已经坏了,就是在坏的路上。但在 Cloud Navite 下,如果我们还是使用传统的架构,就会产生很多重复浪费。
JuiceFS 就是专门为此而设计的。
架构
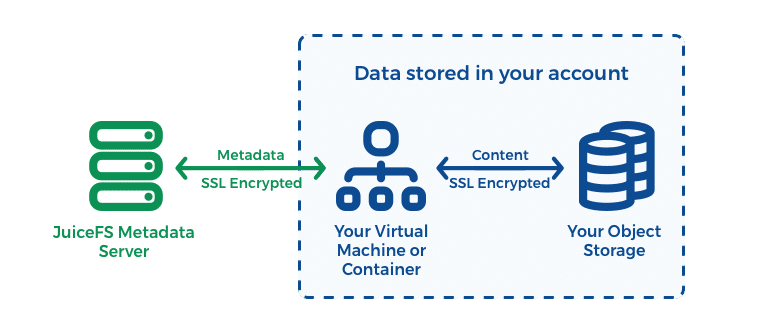

JuiceFS 的 Metadata Service 是一组基于 Raft 协议实现的高可用集群,请求都经由 Leader 节点收发。
Object Storage
这里的 Object Storage 即上文的 chunkserver ,在 AWS 上就是 S3。由于 S3 这类对象存储是高可用且能够无限自动扩容的,这种架构的优势在于可以让不用再运维一个 chunkserver 集群。
性能
由于 S3 本身并不是给文件系统设计的,它的 first-byte-out-latency 非常高,一般有 100–200 ms ,所以这种做法对于小文件肯定是完全不适合的。但如果是针对大文件的场景,这个 100 ms的延迟其实影响并不大,由于 S3 本身就是一个分布式的存储,在本地机器带宽足够的情况下,其吞吐量甚至能够达到 100 Gb/s。
对于顺序读与顺序写请求来说,只要本地能够不停地从 metadata service 上预读到后续的 chunk 位置信息,那么其相较于本地文件系统的差异就可以进一步缩小。
其他方案:Shared Block Storage
上面说的是用 Object Storage 来实现 chunkserver,还有一种更加另类的实现是,直接在块存储层实现共享,使得上层文件系统直接变成一个分布式的文件系统。目前国内能够看到的也只有阿里云开始了内测。